นักการตลาดสายวิเคราะห์ข้อมูลหลายๆ ท่าน คงคุ้นเคยหรือเคยได้ยินคำว่า “Metadata” ซึ่งหมายถึงข้อมูลที่ใช้เพื่ออธิบายหรือนิยามข้อมูลหลัก โดยสิ่งนี้เองจะช่วยให้เราสามารถทำความเข้าใจ จัดระเบียบ ค้นหา และจัดการข้อมูลนั้นได้ง่ายขึ้น พูดง่ายๆ ค่ะว่าเป็นข้อมูลเกี่ยวกับข้อมูลหรือ “ข้อมูลเบื้องหลัง” ที่ให้ข้อมูลเพิ่มเติมเกี่ยวกับไฟล์หรือเนื้อหาที่เราต้องการนำมาวิเคราะห์
โดยปกติแล้วถ้าข้อมูลใดๆ มีการทำ Metadata ไว้ดีจะทำให้การนำข้อมูลมาใช้งาน/ วิเคราะห์ หรือหา Insights ต่างๆ ต่อเป็นไปได้ง่าย,,,, แต่ถ้าข้อมูลเมทาดาทามีคุณภาพต่ำหรือไม่เพียงพอที่จะอธิบายลักษณะหรือบริบทของข้อมูลหลักอย่างชัดเจนและแม่นยำแล้ว,, คำถามที่สำคัญก็คือ เราจะจัดการกับ Information ลักษณะนั้นอย่างไรกันนั่นเองค่ะ
ในบทความนี้ นิกเลยอยากจะพาทุกท่านแก้ไขปัญหานี้ไปพร้อมๆ กันด้วยการอาศัยความสามารถของ Generative AI ที่มีเบื้องหลังเป็น LLMs ซึ่งหมายความว่าเราไม่จำเป็นต้องเป็น Developer หรือ Big data engineer เราก็สามารถแก้ไขปัญหานี้โดยเบื้องต้นได้ด้วยตัวเอง,, Let’s go (≧∇≦)ノ
โดยปกติแล้วการพยายามทำความเข้าใจข้อมูลจำนวนมากที่ User หรือ Stakeholder ป้อนเข้ามาโดยไม่ได้รับการดูแลเป็นงานที่ต้องใช้สมองมากและใช้เวลานาน ซึ่งท้ายสุดแล้วเราอาจต้องตัดจบลงด้วยการสุ่มตัวอย่างข้อมูลและได้ข้อมูลเชิงลึกผิวเผินเกินกว่าจะเอาไปใช้อะไรแบบเป็นประโยชน์ได้ (หรือร้ายกว่านั้นคือหลอกตัวเองว่าข้อมูลเหล่านั้นใช้ได้ค่ะ) แต่เมื่อเรามี LLMs (Large Language Models) เช่น ChatGPT, Gemini, etc. เข้ามาการทำงานตรงนี้ก็มีประสิทธิภาพมากขึ้น ซึ่งทำให้เราสามารถ Cleansing data ทำการวิเคราะห์ และสร้างกราฟที่มีประโยชน์ได้ ตลอดจนสามารถช่วยเราหาแนวทางในการจัดการข้อมูลส่วนบุคคล (PII) ได้ด้วย
และความเท่ก็คือ,, ไม่จำเป็นต้อง Cleansing Data ที่แหล่งที่มาของข้อมูล ใช้งานง่ายๆ เหมือนเราใช้เครื่องกรองน้ำค่ะ เพียงแค่เราใส่ Filter ที่คือว่า Generative AI (หรือ LLMs) ปุ๊บ=>> น้ำที่ไหลผ่านก็ใสขึ้นปั๊บ^^
Generative AI ในการจัดการ Metadata
เรามาเริ่มต้นกันที่การใช้ Generative AI ในการทำ Ticket Analysis ค่ะ
*Tickets ใน metadata หมายถึงบันทึกหรือรายการข้อมูลที่เกี่ยวข้องกับเหตุการณ์หรือการกระทำที่เกิดขึ้นในระบบ ซึ่งมักถูกใช้ในระบบการจัดการงานหรือบริการ (เช่น ระบบ IT support, ระบบซอฟต์แวร์สำหรับการติดตามปัญหาของลูกค้า, หรือการจัดการโครงการ) โดย Ticket metadata จะเก็บข้อมูลที่สำคัญเกี่ยวกับ ticket เพื่อช่วยในการติดตาม จัดการ และวิเคราะห์การทำงานหรือการแก้ปัญหาต่าง ๆ ได้อย่างมีประสิทธิภาพค่ะ
ยกตัวอย่างในงานด้านลูกค้า เช่น ระบบการรับเรื่องคืนสินค้า (Return Request System) ที่จะมีหน้าตาของ Ticket Metadata ที่ถูกสร้างขึ้นประมาณนี้ค่ะ:
- Ticket ID: #98765
- Title/Subject: “คำขอคืนสินค้า – โทรศัพท์มือถือไม่ตรงกับคำสั่งซื้อ”
- Description: “ลูกค้าสั่งซื้อโทรศัพท์มือถือรุ่น A แต่ได้รับรุ่น B และต้องการคืนสินค้า”
- Status: “In Progress”
- Priority: “Medium”
- Assigned to: “แผนกคืนสินค้า”
- Customer Name: “นางสาวแมวดำ ชอบมีโอ”
- Customer Contact Info: เบอร์โทรศัพท์, อีเมล
- Created Date: “14 กันยายน 2024, 3:00 PM”
- Due Date: “18 กันยายน 2024, 3:00 PM”
- Tags/Labels: “คืนสินค้า”, “ผิดรุ่น”, “โทรศัพท์มือถือ”
- Resolution Notes: “ส่งคำขอคืนสินค้าไปยังฝ่ายจัดส่งแล้ว รอการตอบรับจากคลังสินค้า”
ซึ่งในกรณีนี้ ticket metadata ช่วยในการจัดลำดับคำขอคืนสินค้าและติดตามสถานะของการคืนสินค้าได้อย่างสะดวก ทีมงานสามารถตรวจสอบรายละเอียดของคำขอคืนสินค้าและดำเนินการตามขั้นตอนที่กำหนดได้อย่างรวดเร็ว รวมถึงสามารถสื่อสารกับลูกค้าได้ง่ายขึ้นเมื่อมีข้อมูลครบถ้วน และสามารถนำเอาข้อมูลเหล่านี้มาหา Insights ต่อไปได้
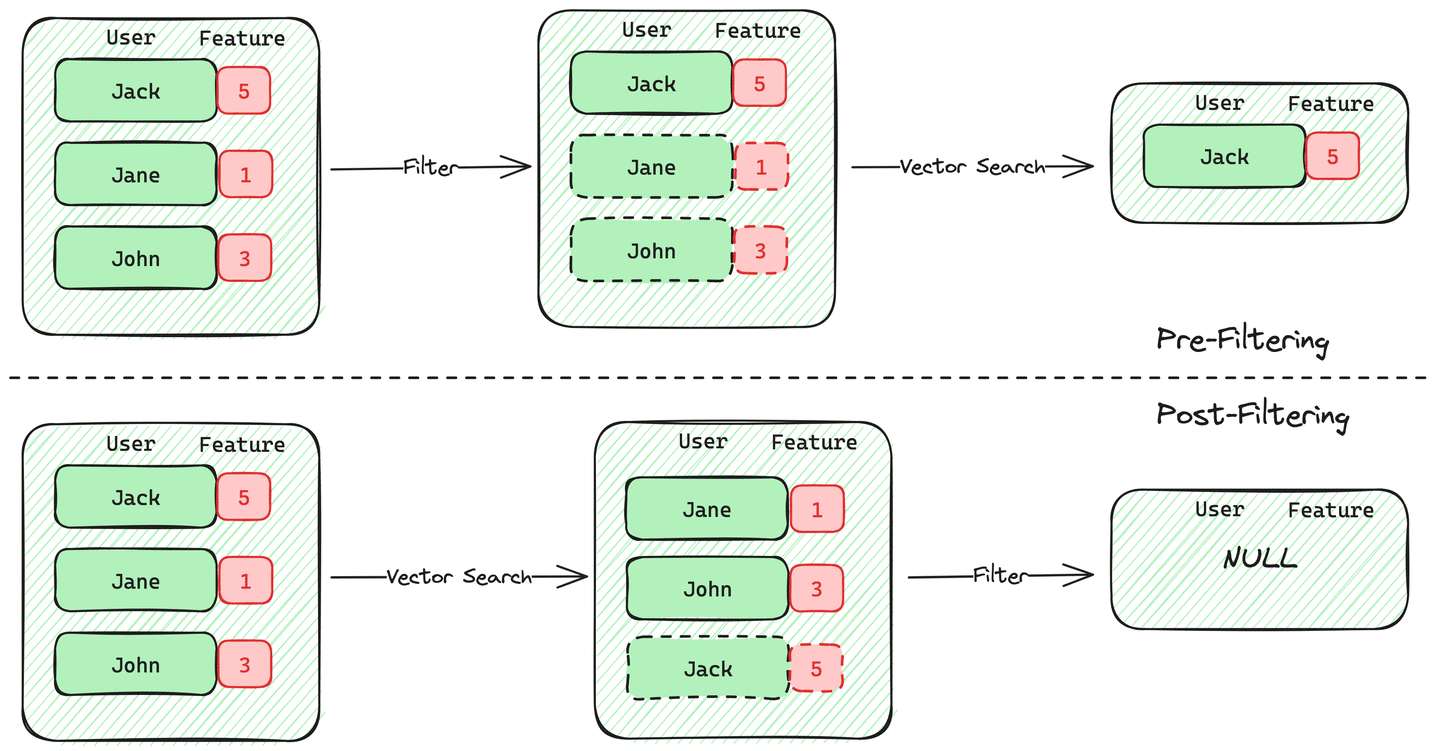
โดยจากข้อมูลทั้งหมดที่ถูกสร้างขึ้นมา จะเห็นได้ว่ามีรายละเอียดที่ค่อนข้างเยอะมาก,, ดังนั้นสิ่งแรกที่เราจะทำก็คือ “Filter Out All tickets” ให้เหลือเพียงแค่ “Domain Tickets” ที่เราต้องการ
#1 การ Filter เลือกเฉพาะข้อมูลที่เกี่ยวข้อง (การลดจำนวน Working set)
เมื่อเราเข้าใจแล้วว่า Tickets คืออะไร เราจะมาเริ่มกันที่การลดจำนวน working set ของ tickets โดยส่วนนี้จะเป็นการกรองเพื่อให้เหลือแต่สิ่งที่เกี่ยวข้องเฉพาะกับทีมหรือ Insights ที่เราต้องการเท่านั้นค่ะ
ซึ่งโดยปกติแล้ว กระบวนการ Filter นี้สามารถทำได้หลากหลายวิธีด้วยกันไม่ว่าจะเป็น Graph search, vector search, etc., และเราจะมาใช้ ChatGPT ในการช่วยเราทำสิ่งนี้กัน,,
โดย Concept ก็คือการพยายามจัดการกับปัญหาหลักที่เราเจอได้บ่อยๆ ได้แก่ metadata ที่ไม่สมบูรณ์หรือไม่มีคุณภาพ (poor metadata) ซึ่งทำให้ยากต่อการแยกแยะว่า ticket ไหนเป็นของทีมใดหรือตรงกับงานที่เราต้องการ ซึ่งเกิดจากการที่ไม่ได้มีการระบุส่วนงาน หรือหัวข้อที่เกี่ยวข้องกับแต่ละ ticket หรือไม่มีหมวดหมู่ที่ชัดเจนสำหรับ ticket นั้น ๆ ทำให้เราเจอกับการทำงานด้วย ข้อมูลที่ไม่เป็นระเบียบ เช่น ข้อมูลที่เป็นอิสระ (free form data) หรือข้อมูลพื้นฐาน (basic facts) ที่ถูกบันทึกโดยอัตโนมัติสำหรับแต่ละ ticket (ส่วนนี้เจอได้บ่อยๆ ในข้อมูลจากลูกค้า)
ดังนั้นการใช้ Generative AI เพื่อวิเคราะห์ข้อมูลที่เป็นกลางจะมาช่วยในส่วนนี้ได้,, มาดูตัวอย่าง Prompts กันค่ะ,,
[1] กรณีเรามี ticket จำนวนมาก แต่ต้องการส่งเฉพาะ ticket ที่เกี่ยวข้องกับส่วนงานวิเคราะห์ข้อมูลลูกค้า
#Prompt: Please analyze the following tickets only if they are related to “Data Technologies”. Ignore any tickets that are not in this category.
Tickets:
- Ticket 1: Subject: “Database server down”, Description: “The server handling our databases is offline.”
- Ticket 2: Subject: “CRM login issue”, Description: “Users are unable to log into the CRM system.”
- Ticket 3: Subject: “Slow network in the office”, Description: “Office employees report network slowdowns.”
[2] กรณีมีเรามีข้อมูลลูกค้าที่ไม่เกี่ยวข้องจำนวนมากใน dataset และต้องการสรุปเฉพาะข้อมูลของลูกค้ากลุ่มที่ซื้อสินค้าประเภท “Smartphones” เท่านั้น
Prompt: Please summarize only the customer tickets that involve the purchase of “Smartphones”. Ignore any other product categories.
Customer support tickets:
- Customer 1: Product: “Smartphone”, Issue: “Screen cracked upon delivery.”
- Customer 2: Product: “Laptop”, Issue: “Battery not charging properly.”
- Customer 3: Product: “Smartphone”, Issue: “Unable to connect to Wi-Fi.”
หลังจากที่เราได้ข้อมูลที่เกี่ยวข้องกับ Insights ที่เราต้องการแล้ว ขั้นตอนที่ 2 ของการทำงานกับระบบ ticketing คือการดึงข้อมูลจากฟิลด์ “description” และ metadata อื่นๆ ที่มีความสำคัญต่อการวิเคราะห์ปัญหา โดยฟิลด์ description คือช่องทางหลักที่ผู้สร้าง ticket (เช่น ลูกค้าหรือ User) ใช้ในการสื่อสารกับทีมสนับสนุน โดยการอธิบายปัญหาหรือผลกระทบทางธุรกิจ ดังนั้นแม้ว่าผู้สร้าง ticket อาจทำผิดพลาดในข้อมูลอื่นๆ ได้ แต่ฟิลด์นี้เป็นสิ่งที่เราเจอว่าผู้กรอกไม่ค่อยพลาด และส่วนนี้เองที่เราจะมาหา Insights,, ดังนั้นมาดูตัวอย่างของ Propmts กันค่ะ
[1] การวิเคราะห์การร้องเรียนของลูกค้าโดยใช้ฟิลด์ description: ต้องการวิเคราะห์การร้องเรียนจากลูกค้าในเรื่องการบริการหลังการขายที่เกี่ยวข้องกับสินค้าประเภท “Smartphones”
Prompt: Please analyze the following customer complaint descriptions related to “Smartphones”. Focus on identifying common issues and patterns.
Ticket Descriptions:
- “The smartphone screen cracked after one week of use. I would like a replacement.”
- “The phone overheats while charging and causes discomfort when holding.”
- “The camera quality is not as advertised; pictures appear blurry.”
- “The phone was delivered with a damaged battery, and it won’t charge.”
[2] กรณีต้องการตรวจสอบข้อมูลการตอบรับจากลูกค้าที่ใช้บริการหลังการขาย โดยมุ่งเน้นที่การวิเคราะห์ความพึงพอใจของลูกค้าเกี่ยวกับบริการ
Prompt: Please summarize and evaluate the following customer feedback descriptions about after-sales service. Focus on determining if the feedback is generally positive, negative, or neutral.
Ticket Descriptions:
- “The service was quick and the support team was very helpful in solving the issue.”
- “I had to wait for over two weeks to get a response, and my problem is still not resolved.”
- “The technician was knowledgeable and fixed my issue within an hour.”
- “The support team was unresponsive and I had to escalate the issue several times.”
ซึ่งสิ่งที่จะได้จาก ChatGPT ก็คือการสรุปและจัดหมวดหมู่ feedback เป็นบวก ลบ หรือเป็นกลางตามคำอธิบายจากฟิลด์ description ทำให้เราได้ Insights เรื่อง Sentiment Analysis ของลูกค้าเพิ่มเติมได้นั่นเองค่ะ😎😄
Last but not Least..
ท้ายสุด,, นิกหวังเป็นอย่างยิ่งว่าเพื่อนๆ จะได้ไอเดียในการใช้ Generative AI เพื่อดึง Insights จากข้อมูลที่ไม่สมบูรณ์หรือมี Poor Metadata ออกมาได้ โดยการโฟกัสที่ฟิลด์สำคัญเช่น description หรือข้อมูลที่เป็น “ข้อเท็จจริง” ซึ่งช่วยให้เรายังคงสามารถดึงข้อมูลเชิงลึกออกมาได้อย่างแม่นยำ เพื่อเพิ่มคุณค่าของข้อมูลที่ดูเหมือนไม่มีคุณค่าให้กลายเป็นแหล่งข้อมูลสำคัญสำหรับการตัดสินใจทางธุรกิจในอนาคต 😊📈