สวัสดีค่ะทุกท่าน )ヽ(✿゚▽゚)ノ ในช่วงสัปดาห์ที่ผ่านมามีการถกกันในประเด็นที่นับว่าน่าสนใจมากๆ ในโลกยุคดิจิทัลที่เทคโนโลยีสามารถเลียนแบบศิลปะได้ใกล้เคียงความจริงมากกว่าที่เคย นั่นคือปรากฏการณ์ที่ AI สามารถสร้างภาพลายเส้นในสไตล์ Studio Ghibli (จิบิ, ちび) ได้อย่างแนบเนียนสุดๆ เพียงแค่พิมพ์ข้อความ ซึ่งทำให้ Generative AI กลายเป็นทั้งเครื่องมือแห่งความคิดสร้างสรรค์ และจุดเริ่มต้นของคำถามเชิงจริยธรรมที่สะท้อนถึง “ตัวตนของงานศิลปะ” อย่างลึกซึ้ง โดยเบื้องหลังของ AI Model ที่ใช้สร้างภาพเหล่านี้มีทั้ง DALL-E จาก OpenAI, Stable Diffusion หรือโมเดลอื่นๆ จากหลายค่าย
ทำให้เราสามารถเปลี่ยนข้อความธรรมดาร่วมกับการใช้รูปตัวอย่าง ให้กลายเป็นภาพที่มีอารมณ์และรายละเอียด คล้ายกับว่ามีศิลปินลงมือวาดเอง ซึ่งกระบวนการสร้างนี้ไม่เพียงแค่สะท้อนความก้าวหน้าทางวิทยาการ แต่ยังเปิดประเด็นทางสังคมและกฎหมายในระดับสากลเกี่ยวกับความเป็นเจ้าของ ความสร้างสรรค์ และอนาคตของศิลปะในยุคที่ “จิตวิญญาณ” อาจถูกเขียนด้วยรหัส
ในบทความนี้นิกเลยอยากพาทุกท่านไปทำความเข้าใจเจาะลึกเบื้องหลังกระบวนการอันซับซ้อนของเทคโนโลยี Generative AI อัลกอริทึมแรกๆ ที่เป็นพื้นฐานของอีกหลายโมเดลในยุคนี้อย่าง Stable Diffusion ที่ใช้หลักการ “แพร่ข้อมูลแบบเสถียร ” (Stable Diffusion) ผ่านโมเดล Deep Learning ที่ผสมผสานการทำงานของ VAE, UNet และ CLIP เข้าด้วยกัน
#1 ทำความเข้าใจ Image Generation เบื้องต้น
การทำ Image generation คือเรื่องของการสร้างภาพด้วยโปรแกรมภาษาต่างๆ เช่น Python ด้วย Algorithm หรือ model ที่ชื่อ Stable diffusion (หรืออื่นๆ) ซึ่งในการสร้างภาพจะมีการควบคุมผลลัพธ์ โดยตัวแรกจะเป็นข้อความคือการบอกว่าเราต้องการอะไร ต้องการภาพประมาณไหน หรือนั่นก็คือ Prompt นั่นเองค่ะ และส่วนที่ 2 ก็คือการควบคุมผลลัพธ์ด้วยการให้ภาพต้นแบบเพื่อให้เวลาสร้างภาพให้อิงจากภาพนี้ ซึ่งการสร้างภาพแบบ Low code หลายๆท่าน อาจคุ้นเคยทั้งในส่วน DALL-E ใน ChatGPT หรือ Stable diffusion เป็นต้น
โดยการสร้างภาพจากข้อความ ตัว Input ที่เราป้อนเข้าไปจะเป็นข้อความ ส่วนขนาดก็ขึ้นอยู่กับ Platform กำหนด และเงื่อนไขที่มีไว้ให้ โดยลักษณะของภาพที่ได้เราสามารถกำหนดได้ว่าเป็น Style ไหน โดยสิ่งที่เราใส่เข้าไปจะเป็น prompt
#2 Stable Diffusion Model คืออะไร?
Stable Diffusion เป็นหนึ่งในโมเดล Generative AI ที่สามารถ “สร้างภาพจากข้อความ (Text-to-Image)” ได้ โดยเริ่มจากการป้อนข้อความ (prompt) แล้วโมเดลจะสร้างภาพขึ้นมาตามความหมายที่เข้าใจ นอกจากนี้ยังสามารถรับอินพุตเพิ่มเติม เช่น แบบร่างหรือภาพต้นแบบ เพื่อช่วยควบคุมผลลัพธ์ได้แม่นยำยิ่งขึ้น
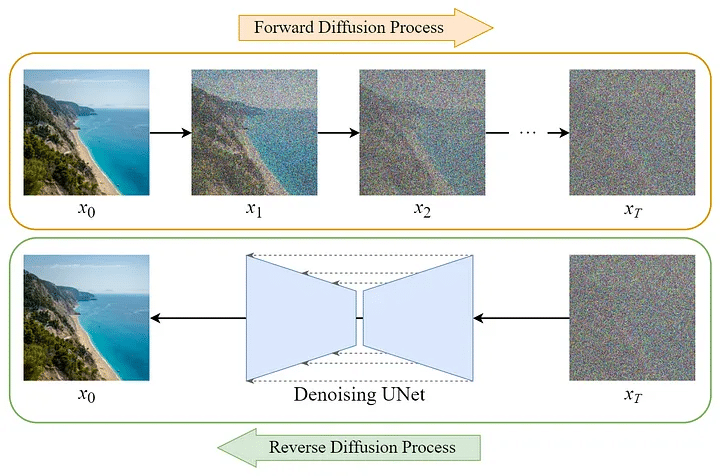
Concept ของ Stable diffusion ถ้าเราจะแปลเป็นไทยได้ว่า แบบจำลองการแพร่แบบเสถียร โดยคำว่าการแพร่ก็คือ Diffusion คำถามคือแล้วแพร่อะไร? ==>>คำตอบคือเป็น “การแพร่ของสัญญาณ” โดยเฉพาะ Gaussian Noise (สัญญาณรบกวนแบบระฆังคว่ำ) ซึ่งมี 2 ขั้นตอนหลัก:
Forward Diffusion : เติม noise ลงในภาพดีๆ ให้เสียหาย (เละ) ไปเรื่อยๆReverse Diffusion : ให้โมเดลเรียนรู้วิธี “ลบ” noise และกู้ภาพกลับมาใหม่อย่างเป็นระเบียบ
อธิบายให้เห็นภาพง่ายๆ เลยก็คือการแพร่ไปข้างหน้า และการแพร่แบบถอยหลัง โดยจากเดิมเริ่มต้นที่การแพร่ไปข้างหน้าด้วยการเติม Noise เข้าไป จนภาพดีๆ กลายเป็นภาพเละๆ (Forward diffusion) หรือจากนั้นก็ให้ Model เรียนรู้เพื่อทำให้ภาพเสียๆ กลับมาเหมือนเดิม หรือกอบกู้ภาพเละๆ ให้กลับมาดีเหมือนเดิม (Reverse diffusion) โดยกระบวนการทำก็คือการพยายามกำจัด noise ออกไป เพื่อพยายามเอาเม็ด pixel เรียงตัวกลับมาให้สวยงามเหมือนเดิม
ดังนั้นลึกๆ Stable Diffusion model คือกระบวนการที่พยายามกำจัดสิ่งรบกวนออกไปจากภาพ
#3 กระบวนการของ Stable diffusion
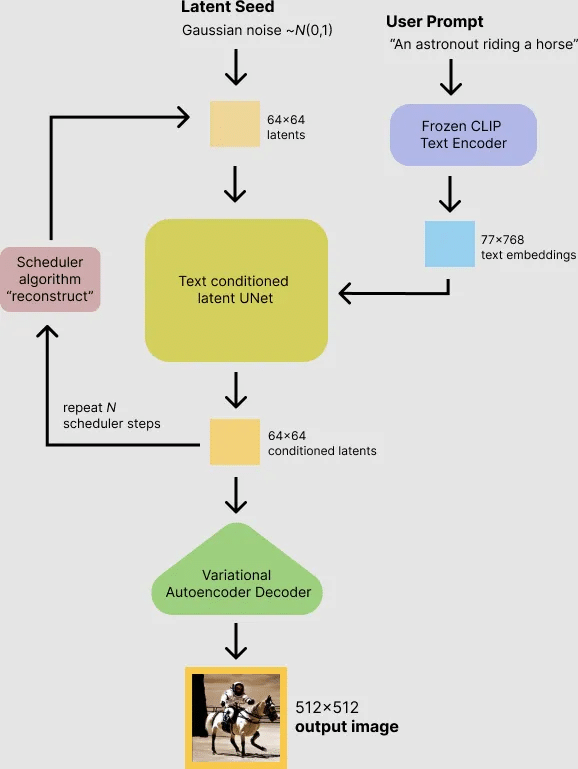
การทำงานของ Stable Diffusion (SD) เป็นกระบวนการที่ประกอบไปด้วยหลายขั้นตอนที่ทำงานร่วมกันเพื่อสร้างภาพจากข้อความ โดยแบ่งออกเป็น 3 ขั้นตอนหลักที่สำคัญดังนี้ค่ะ
3.1 การเตรียม Dataset
ในขั้นตอนการเตรียมข้อมูล (Dataset) สำหรับการฝึกสอนโมเดล ภาพและข้อความบรรยาย (Captions) จะถูกจัดเตรียมในคู่ (Image-Text pairs) ซึ่งทำให้โมเดลสามารถเรียนรู้การเชื่อมโยงระหว่างภาพและคำบรรยายได้ โดยข้อความจะช่วยให้โมเดลเข้าใจลักษณะของภาพ และสามารถเชื่อมโยงภาพกับคำบรรยายในลักษณะต่าง ๆ โดยการใส่ Adjective ที่ช่วยบรรยายลักษณะของภาพ ซึ่งทำให้โมเดลสามารถสร้างภาพที่มีความหมายตามคำบรรยายได้
เช่น ภาพแมวดำ กับคำบรรยาย เช่น แมวดำอ้วนกำลังนอนหงายท้องรอให้จกพุง โดยทั้ง 2 ส่วนนี้จะเรียกว่าคู่ train โดยตัวภาพอาจสามารถใช้ภาพซ้ำได้ แต่เปลี่ยนข้อความบรรยาย ซึ่งจริงๆ ตอนบรรยายจะใส่เป็น Adjective ค่อนข้างเยอะ (สิ่งที่เรากำลังทำอยู่นี้เรียกว่า image to text ซึ่งเราอาจสามารถให้ GenAI ตัวอื่นช่วยบรรยายให้ได้—-ตอนนี้เรากกำลังทำ image to text ก่อนที่จะไปทำ text to image)
และที่เราต้องใส่คำบรรยายเยอะๆ เพราะว่าให้ model เข้าใจว่าภาพเหล่านี้มีนัยยะเชื่อมโยงกับอะไรบ้าง ซึ่งกระบวนการนี้เราเรียกว่ากรทำ “Image captioning” ซึ่งตัวโมเดลจะสร้างได้เฉพาะสิ่งที่ผ่านการ Train มาแล้วเท่านั้น ดังนั้นถ้าเราให้สร้างภาพที่โมเดลไม่รู้จักเช่น ภาพ ปณยา สุดตา (ชื่อนิกเองค่ะ^^) โมเดลอาจสร้างไม่ได้ หรืออาจจะมั่วๆ มาค่ะ (^∀^●)ノシ
3.2 การฝึกสอนโมเดล
เมื่อเตรียมข้อมูลได้แล้ว การ Train โมเดลจะประกอบไปด้วย 3 ส่วนหลักที่ทำงานร่วมกัน:
(1) VAE (Variational Autoencoder)
VAE Encoder : มีหน้าที่แปลงภาพให้เป็นข้อมูลขนาดเล็กที่เรียกว่า latent vector ซึ่งช่วยลดขนาดของข้อมูลให้เล็กลงและสะดวกต่อการประมวลผล
*การเข้ารหัส คือการที่เรากำลังจะแปลงอะไรบางอย่างให้เล็กลง โดยการเข้ารหัสเพื่อทำอะไรที่เยอะๆ ให้ย่อให้สั้นลงมา ทำหน้าที่หลักในการลดขนาดของข้อมูล เช่นสมมติสิ่งที่เราป้อนเข้าไปเป็นตัวเลข 100 ตัว เข้า End-coder อาจเหลือแค่ 5 ตัวที่เป็นตัวแทนของชุดข้อมูลทั้งหมด หรือเป็นการสกัดคุณลักษณะสำคัญ อารมณ์ประมารเหมือนเราเลือก ส.ส. ตัวนี้เลยเป็นตัวแทนสำคัญที่จะเข้าสู่กระบวนการประมวลผลต่อไป เพื่อให้สามารถประมวลผลได้ดีขึ้น/ไวขึน (เปลี่ยนภาพ เป็น Vector (ตัวเลข))
VAE Decoder : ใช้ในการแปลงข้อมูลที่ได้จาก latent vector กลับเป็นภาพอีกครั้ง โดยการฟื้นฟูข้อมูลจากการแปลงให้กลับมาเป็นภาพในรูปแบบเดิม
*การถอดรหัสทำหน้าที่ในการฟื้นคืนข้อมูล 5 ตัวก่อนหน้านั้นให้เป็น 100 ตัวเหมือนเดิม (หรือเป็นภาพสวยๆ เหมือนเดิม) ซึ่งจะเกิดหลังจากที่เราจัดการข้อมูลน้อยๆ กลับเสร็จเรียบร้อยแล้ว (เปลี่ยน Vector (ตัวเลข) ให้กลับไปเป็น ภาพ)
(2) U-Net
U-Net เป็นโครงข่ายประสาทเทียม (Neural Network) ที่ออกแบบมาเพื่อการลด Noise ในภาพ โดยในกรณีของ Stable Diffusion จะทำหน้าที่กำจัด Noise ที่เกิดขึ้นในกระบวนการสร้างภาพ เพื่อให้ได้ภาพที่สะอาดและมีความคมชัด โดย U-Net จะทำงานกับชุดข้อมูลที่ถูกแปลงมาเป็นเวกเตอร์จาก VAE Encoder
โดยโครงสร้างเป็น CNN เรียงต่อกันเป็นตัว U ที่เมื่อเราป้อนชุดตัวเลขเข้าไป สิ่งที่ออกมาก็เป็นตัวเลขเหมือนเดิม ซึ่งจากเดิม UNet เกิดในปี 2015 เพื่อการแบ่งส่วนภาพ เช่นการ Segment เนื้องอก เซลล์ผิดปกติเป็นต้น
แต่จริงๆ แล้ว UNet สำหรับ Stable Diffusion มีความสามารถในการลด Noise ออกไปเป็นภาพที่สะอาดสวยงาม ไม่มี Noise ฉะนั้นหน้าที่ของ Unet ใน SD มีหน้าที่เดียวเลย คือการทำ Cleaning แต่ UNet ไม่ได้ทำกับภาพโดยตรง แต่ทำกับชุดตัวเลขที่เป็น Vector ที่ออกมาจาก VAE End-coder แล้ว
ดังนั้นสิ่งที่ได้รับการ Train จริงๆ ในส่วนของ Stable Diffusion Model ก็คือ UNet นั่นเองค่ะ ฉะนั้น Parameter ที่อยู่ใน UNet จะต้องได้รับการฝึกสอน คือเหมือน Train ให้ UNet กวาดบ้านให้สะอาดเพื่อให้ได้ชุดข้อมูลที่ไม่มี Noise นั่นแหละ
(3) CLIP (Contrastive Language-Image Pretraining)
CLIP ทำหน้าที่เข้ารหัสข้อมูลข้อความให้กลายเป็นชุดตัวเลขที่เรียกว่า Vector (ในที่นี้ก็คือข้อความบรรยายของภาพนั่นเองค่ะ) Text-embedding คือเป็นการเข้ารหัสข้อมูลข้อความ ซึ่งตรงนี้จะอยู่ในด่านแรกของโมเดลเลย โดยข้อความจะเข้ามาใน 2 ส่วนคือ มาจาก prompt และมาจากการ train model โมเดล โดยจะใช้ CLIP ในการแปลงข้อความให้เป็นเวกเตอร์และส่งไปยัง U-Net เพื่อลด Noise และสร้างภาพ ดังนั้นสรุปว่าเรามีการใช้ CLIP 2 ที่คือทั้งตอนใช้งานโมเดลจริง และการฝึกสอน
3.3 การนำโมเดลไปใช้งาน
เมื่อโมเดลฝึกเสร็จแล้ว เราสามารถนำมาใช้งานได้โดยการป้อนข้อมูลจากผู้ใช้ เช่น ข้อความ (Prompt), ภาพต้นแบบ, หรือแม้แต่ภาพร่าง (Sketch) ในขั้นตอนนี้ CLIP จะทำการแปลงข้อความจากผู้ใช้ให้เป็นเวกเตอร์เพื่อให้ U-Net ใช้ในการลด Noise และสร้างภาพใหม่
หลังจากที่ U-Net ได้ลด Noise และสร้างภาพที่สะอาดขึ้นแล้ว ภาพที่ได้จะถูกส่งผ่าน VAE Decoder เพื่อแปลงกลับเป็นภาพที่เสร็จสมบูรณ์ โดยในระหว่างกระบวนการนี้โมเดลจะประเมินผลความแตกต่างระหว่างภาพที่ได้กับภาพต้นฉบับ (Loss Function) เพื่อปรับปรุงผลลัพธ์ให้ดีขึ้น
คำถามสำคัญคือ: แล้ว 3 ส่วนที่กล่าวมา (VAE, U-Net, CLIP) อยู่ตรงไหนในกระบวนการของ Stable Diffusion (SD) กันแน่?
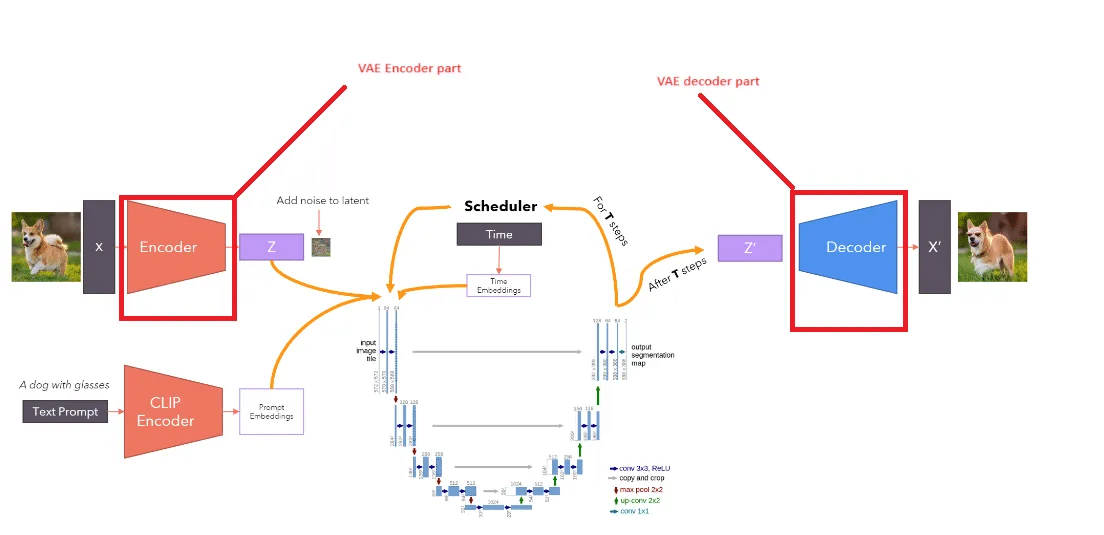
ในการ Train โมเดล SD เราจะเริ่มต้นจากการนำ Input 2 อย่าง คือ ภาพ และ คำบรรยายของภาพนั้น เข้ามาใช้งาน โดยสิ่งแรกที่ต้องทำคือหยิบภาพจากชุดข้อมูลที่เราเตรียมไว้ขึ้นมาหนึ่งภาพ เรียกว่า img input จากนั้นส่งภาพนี้เข้าไปยัง VAE Encoder เพื่อแปลงจากภาพให้อยู่ในรูปของเวกเตอร์ที่เรียกว่า latent vector (หรือเวกเตอร์ที่มีความสำคัญ) ซึ่งเป็นเวกเตอร์ที่ยังสะอาด ไม่มีการปนเปื้อนด้วยสัญญาณรบกวน (noise)
จากนั้นเราจะทำการ เติม noise เข้าไปใน latent vector นี้ ซึ่งมักใช้ noise แบบ Gaussian noise (ลักษณะการกระจายแบบระฆังคว่ำ) ผลลัพธ์ที่ได้จะกลายเป็นเวกเตอร์ที่มี noise ปนอยู่
ต่อมาจะเข้าสู่กระบวนการของ U-Net ซึ่งทำหน้าที่หลักในการ “คัดแยก noise” ออก โดย noise ที่ถูกเติมเข้าไปใน SD จะเป็นลักษณะของ additive noise (เป็นการปนเปื้อนที่เพิ่มเข้าไปจากเดิม) ซึ่งอาจมีแบบ multiple noise ด้วยแต่ไม่ค่อยนิยม ในกระบวนการนี้ U-Net จะทำซ้ำหลายครั้งเพื่อพยายามลด noise ออกไปให้มากที่สุด
คำถามก็คือ: แล้วรู้ได้อย่างไรว่า U-Net กวาดบ้านเกลี้ยงดีแล้วหรือยัง? คำตอบคือ ต้องมี “คนคอยบอก” ว่า Unet ทำดีแค่ไหน ซึ่งคนๆ นั้นก็คือ CLIP
CLIP จะรับข้อความ prompt ที่เราป้อนเข้ามา แล้วแปลงเป็นเวกเตอร์ข้อความ จากนั้นส่งข้อมูลนี้ให้กับ U-Net โดยตรง เพื่อให้ U-Net ใช้เวกเตอร์จากข้อความมา “กำกับ” การทำความสะอาดเวกเตอร์ภาพที่มี noise อยู่ กล่าวคือ U-Net จะรับ input 2 อย่างพร้อมกัน คือ
เวกเตอร์ภาพที่มี noise
เวกเตอร์คำบรรยาย (จาก prompt ที่ผ่าน CLIP)
credit: Research Gate
เมื่อ U-Net ทำหน้าที่ลบ noise จนได้เวกเตอร์ที่ใกล้เคียงกับเวกเตอร์ภาพจริงแล้ว เวกเตอร์ที่สะอาดนี้จะถูกส่งผ่าน VAE Decoder เพื่อแปลงกลับออกมาเป็นภาพอีกครั้ง (เรียกว่า imgout1 หรือร่างภาพแรก) คำถามที่ตามมาคือ: แล้วเราจะรู้ได้อย่างไรว่า ภาพที่ได้ออกมานั้น “ดีพอแล้ว”?
คำตอบคือ เราจะใช้กระบวนการ คำนวณค่าความผิดพลาด (Loss) โดยการนำภาพที่ได้ไปเทียบกับภาพต้นฉบับ หากยังมีความแตกต่างมาก Loss ก็จะสูง ซึ่งค่าความผิดพลาดนี้จะถูกใช้ในการ ปรับพารามิเตอร์ (Parameter) ภายใน U-Net เพื่อให้การลด noise รอบต่อๆ ไปแม่นยำยิ่งขึ้น โดยจะทำกระบวนการนี้ซ้ำไปหลายรอบ เช่น 50,000 รอบ ซึ่งกระบวนการเรียนรู้นี้อาศัยโครงข่ายประสาทเทียม (Neural Network: NN) ทั้งหมด
สรุปคือ ในกระบวนการฝึกสอนโมเดล SD จะมี โมเดลหลักที่ต้องเรียนรู้จริงๆ คือ U-Net เพียงตัวเดียว โดยการฝึก 1 รอบของข้อมูลทั้งหมด (Train ครบทุกคู่ของภาพและข้อความ) จะเรียกว่า 1 Epoch ส่วน VAE และ CLIP ไม่ได้ถูก Train โดยตรงในกระบวนการนี้ แต่ทำหน้าที่ในการแปลงข้อมูลเพื่อช่วยให้ U-Net สามารถเรียนรู้ได้
หลังจากการฝึกจบ เราจะได้โมเดล SD ที่สามารถนำไปใช้งานได้จริงนั่นเองค่ะ (☞゚ヮ゚)☞
ดังนั้นเมื่อเรานำโมเดลที่ Train เสร็จแล้วมาใช้งานจริง สิ่งที่เราทำคือ ป้อนข้อความ (Prompt) เข้าไป จากนั้น CLIP จะทำหน้าที่แปลงข้อความนั้นให้เป็นเวกเตอร์ ซึ่งเป็นตัวแทนความหมายของข้อความนั้น เมื่อได้เวกเตอร์คำสั่งแล้วก็จะถูกนำไป สั่ง U-Net เพื่อเริ่มกระบวนการสร้างภาพ
คำถามคือ: แล้ว U-Net จะเริ่มต้นจากตรงไหน ?
คำตอบคือ: U-Net จะเริ่มจากการสุ่มเวกเตอร์ชุดหนึ่งขึ้นมาแบบสุ่ม (random noise vector) ซึ่งไม่ได้มีความหมายหรือโครงสร้างของภาพใดๆ ทั้งสิ้น เป็นเพียงชุดตัวเลขแบบมั่วๆ แล้วจากนั้นจึงเริ่มกระบวนการลบ noise ตามคำสั่งจาก CLIP ที่แปลง prompt ไปแล้ว
เวกเตอร์ที่ได้จาก U-Net ยังไม่ใช่ภาพทันที แต่จะต้องนำไปผ่าน VAE Decoder เพื่อแปลงกลับให้กลายเป็นภาพ ซึ่งภาพที่ออกมาจะมีคุณภาพดีแค่ไหนก็ขึ้นอยู่กับว่า U-Net ได้รับการฝึกมาดีแค่ไหน
ดังนั้นจะเห็นได้ว่า ในขั้นตอนการฝึกสอน (Train) เราใช้ทั้ง VAE Encoder และ Decoder ในการใช้งานจริง (Inference) เราใช้แค่ VAE Decoder เพียงอย่างเดียว
ชวนคิด =>>
คหสต. นิกมองว่า Generative AI เป็นเทคโนโลยีที่น่าทึ่งมากๆ ทั้งในแง่การทำงานที่ช่วยให้เราสามารถสร้างภาพจากข้อความได้อย่างแม่นยำ แต่ในขณะเดียวกัน เราก็ต้องเข้าใจว่าเทคโนโลยีแบบนี้มีพลังมากพอจะสร้างแรงกระเพื่อม เช่นกรณีของ McDonald’s เม็กซิโก ที่ใช้ AI สร้างภาพสไตล์ Ghibli จนเกิดเสียงวิจารณ์เรื่องลิขสิทธิ์ เพราะฉะนั้นการเข้าใจโมเดลอย่างรอบด้าน ไม่ใช่แค่เพื่อใช้งานได้ดี แต่เพื่อใช้อย่างมีจริยธรรม คือสิ่งสำคัญที่ทุกคนควรใส่ใจค่ะ ヾ(•ω•`)o