สวัสดีค่ะทุกท่าน,, จากบทความที่แล้ว “การใช้ NotebookLM เพื่อสร้าง AI Podcast แบบ Step by Step” ที่เราได้สร้าง AI Podcast ของเราเองขึ้นมาด้วยพลังของ NotebookLM ในบทความนี้นิกเลยอยากชวนทุกท่านมาทำอะไรที่ล้ำขึ้นไปอีกด้วยการสร้าง Dynamic Podcast Generator ของเราเอง ซึ่งได้ทำหน้าที่เป็น AI อัตโนมัติของเราคล้ายกับ NotebookLM ของ Google
ป.ล. บทความนี้จะเป็นการ Coding นิดหน่อยนะคะ รับรองว่าไม่ยากและสามารถทำตามได้แน่นอนค่ะ
โดยรายละเอียดในบทความนี้จะประกอบด้วย การทบทวนแนวคิดเบื้องหลัง เทคโนโลยีที่เกี่ยวข้อง และโค้ดทีละขั้นตอน เพื่อให้เราสามารถควบคุมเสียงและพรอมต์ได้อย่างสมบูรณ์ในการสร้างพอดแคสต์ AI Dynamic Podcast ที่ไม่เหมือนใครของเราเอง,, Let’s go (☞゚ヮ゚)☞
#0 ที่มาจาก Google: NotebookLM และ Illuminate
Dynamic Podcast ที่เราจะสร้างมีต้นแบบมาจากเทคโนโลยี AI ของ Google สองแพลตฟอร์ม ดังนี้ค่ะ
Illuminate: เป็นเทคโนโลยีทดลองของ Google ที่ใช้ AI ในการปรับเนื้อหาให้เข้ากับรูปแบบการเรียนรู้เฉพาะบุคคล โดยจะสร้างเสียงบทสนทนาที่มี AI สองเสียงพูดคุยกันถึงประเด็นสำคัญของงานวิจัย โดยเฉพาะด้านวิทยาการคอมพิวเตอร์ NotebookLM: คือผู้ช่วย AI ส่วนบุคคลที่ช่วยให้ผู้ใช้เจาะลึกหัวข้อต่างๆ โดยการสร้างบทสรุป ตอบคำถาม และช่วยให้เข้าใจเนื้อหาที่ซับซ้อนได้อย่างลึกซึ้ง
โดยแนวคิดหลักที่เรากำลังจะทำคือการเปลี่ยนบทความหรือข้อมูลจำนวนมากให้กลายเป็นบทสนทนาที่น่าสนใจ ซึ่งช่วยให้การบริโภคเนื้อหาต่างๆ เป็นเรื่องที่สนุกและเข้าถึงได้ง่ายขึ้น
ซึ่งเป้าหมายของเราคือการสร้าง AI Podcast ที่มีผู้ดำเนินรายการสองคน (เราจะใช้ “คุณหมอฉลาด” และ “ผู้ช่วย AI อัจฉริยะ” เพื่อให้เป็นตัวอย่างภาษาไทย แต่ทุกท่านสามารถเปลี่ยนชื่อได้ตามที่ต้องการเลยนะคะ^^) โดยนิกจะให้ AI ทั้งสองพูดคุยกันเกี่ยวกับบทความหรือข้อความที่เราป้อน และควบคุมเสียงของ AI แต่ละตัว โดย Prompt สร้างบทสนทนา เพื่อให้ได้ผลลัพธ์ที่เป็นธรรมชาติ และมีอารมณ์ความรู้สึกค่ะ 💬
#1 Tools ที่ใช้สร้าง Dynamic Podcast
โดยหัวใจหลักของการสร้าง Dynamic Podcast Generator ของเราคือการผสมผสานบริการ AI และ Cloud Computing ดังนี้
Google Text-to-Speech (TTS): สำหรับแปลงข้อความเป็นเสียงพูดคุณภาพสูง ด้วยเสียงที่หลากหลายและเป็นธรรมชาติ (สามารถใช้เสียงทดลองใหม่ๆ ที่น่าสนใจได้ด้วยนะคะ)ElevenLabs: สำหรับการสร้างเสียงสังเคราะห์ที่สมจริง หรือแม้แต่การโคลนเสียงของเราเอง เพื่อเพิ่มความเฉพาะตัวให้กับพอดแคสต์ (เป็นตัวเลือกเสริมที่ยอดเยี่ยม)Google Cloud Storage: สำหรับจัดเก็บไฟล์เสียงพอดแคสต์ที่สร้างขึ้นGemini (บน Vertex AI): เป็น AI ของ Google ที่จะทำหน้าที่เป็น “สมอง” ในการแปลงบทความให้กลายเป็นบทสนทนา
#2 การเตรียม Tools และตั้งค่า Environment
และก่อนที่เราจะเริ่มเขียนโค้ดกัน เราต้องตั้งค่า Environment และบัญชีบริการต่างๆ ดังนี้ค่ะ^^
Google Cloud Project:
เข้าสู่ Google Cloud Console
สร้างโปรเจกต์ใหม่ (หากยังไม่มี) หรือเลือกโปรเจกต์ที่มีอยู่
เปิดใช้งาน API ที่จำเป็น:
Vertex AI API Text-to-Speech API Cloud Storage API
สร้าง Service Account Key:
ไปที่ IAM & Admin > Service Accounts
สร้าง Service Account ใหม่ และกำหนดบทบาทที่จำเป็น (เช่น Vertex AI User, Cloud Text-to-Speech User, Storage Object Admin)
สร้างคีย์ JSON และดาวน์โหลดเก็บไว้ในเครื่องของคุณ
สำคัญ: ตั้งค่าตัวแปรสภาพแวดล้อม GOOGLE_APPLICATION_CREDENTIALS ให้ชี้ไปยังพาธของไฟล์ JSON นี้ หรือระบุพาธโดยตรงในโค้ด (แนะนำวิธีแรกเพื่อความปลอดภัย)
ตัวอย่าง (สำหรับ Linux/macOS): export GOOGLE_APPLICATION_CREDENTIALS="/path/to/your/service-account-key.json"
ตัวอย่าง (สำหรับ Windows PowerShell): $env:GOOGLE_APPLICATION_CREDENTIALS="C:\path\to\your\service-account-key.json"
ElevenLabs API Key (ไม่บังคับ แต่แนะนำ):
ไปที่ ElevenLabs.io และสมัครสมาชิก (มีแผนฟรีให้ทดลองใช้)
เข้าถึง Profile > API Key และคัดลอกคีย์ของคุณ
ติดตั้งไลบรารี Python:
เปิด Terminal/Command Prompt ของคุณ
ติดตั้งไลบรารีที่จำเป็น:Bashpip install google-cloud-texttospeech google-cloud-aiplatform requests pydub
สำหรับ pydub: คุณอาจต้องติดตั้ง ffmpeg เพิ่มเติม หากยังไม่มีในระบบ เพื่อใช้ในการรวมไฟล์เสียง. ค้นหาวิธีติดตั้ง ffmpeg สำหรับระบบปฏิบัติการของคุณ (เช่น brew install ffmpeg สำหรับ macOS, ดาวน์โหลดจาก ffmpeg.org สำหรับ Windows)
เลือกสภาพแวดล้อมการเขียนโค้ด:
Google Colaboratory: สะดวกที่สุดสำหรับการเริ่มต้น ไม่ต้องตั้งค่าอะไรมากJupyter Notebook/Lab: เหมาะกับการทดลองและพัฒนาVS Code: สำหรับการพัฒนาโปรเจกต์ที่จริงจัง
#3 การทำ Dynamic Podcast Generator แบบ Step by Step
1. การนำเข้าไลบรารีและตั้งค่าเริ่มต้น
Python
import vertexai
from vertexai.generative_models import GenerativeModel, GenerationConfig, Part
from google.cloud import texttospeech
import os
import json
import requests
from pydub import AudioSegment
# กำหนดค่า Project ID และ Location ของ Google Cloud
# แทนที่ 'YOUR_PROJECT_ID' และ 'us-central1' ด้วยค่าของคุณ
PROJECT_ID = "YOUR_PROJECT_ID"
LOCATION = "us-central1"
vertexai.init(project=PROJECT_ID, location=LOCATION)
# ตั้งค่า ElevenLabs API (หากใช้)
# แทนที่ 'YOUR_ELEVENLABS_API_KEY' ด้วยคีย์ของคุณ
ELEVENLABS_API_KEY = "YOUR_ELEVENLABS_API_KEY"
ELEVENLABS_VOICE_ID_SASCHA = "YOUR_CLONED_VOICE_ID" # หากโคลนเสียงแล้ว
elevenlabs_url = f"https://api.elevenlabs.io/v1/text-to-speech/{ELEVENLABS_VOICE_ID_SASCHA}/stream"
elevenlabs_headers = {
"Accept": "audio/mpeg",
"Content-Type": "application/json",
"xi-api-key": ELEVENLABS_API_KEY
}
# กำหนด Google Text-to-Speech Client
tts_client = texttospeech.TextToSpeechClient()
# กำหนด Map ของเสียงสำหรับแต่ละผู้พูด
# 'คุณหมอฉลาด' ใช้ ElevenLabs (ถ้าคุณโคลนเสียง)
# 'ผู้ช่วย AI อัจฉริยะ' ใช้ Google TTS (en-US-Journey-O เป็นเสียงที่ดีและเป็นธรรมชาติ)
speaker_voice_map = {
"คุณหมอฉลาด": "ElevenLabs",
"ผู้ช่วย AI อัจฉริยะ": "en-US-Journey-O" # เลือกเสียง Google TTS ที่คุณชอบได้
}
2. สร้างบทสนทนาด้วย Gemini
ใช้ Prompt ต่อไปนี้บน Gemini เพื่อเปลี่ยนบทความของเราให้เป็นบทสนทนากันค่ะ
Python
system_prompt = """
คุณคือผู้ดำเนินรายการพอดแคสต์ที่มีประสบการณ์สูง โดยมีผู้ดำเนินรายการสองคนคือ 'คุณหมอฉลาด' และ 'ผู้ช่วย AI อัจฉริยะ'
จากข้อความที่ให้มา เช่น บทความ ให้คุณสร้างบทสนทนาที่น่าสนใจและมีชีวิตชีวาระหว่างคนสองคนนี้
บทสนทนาต้องมีความยาวอย่างน้อย 15,000 ตัวอักษร (เพื่อความเหมาะสมกับพอดแคสต์) และเต็มไปด้วยอารมณ์ความรู้สึก
ในการตอบกลับของคุณ เพื่อให้ฉันสามารถระบุได้ ให้ใช้ชื่อ 'คุณหมอฉลาด' และ 'ผู้ช่วย AI อัจฉริยะ' นำหน้าประโยคเสมอ
คุณหมอฉลาดเป็นผู้เขียนบทความ และผู้ช่วย AI อัจฉริยะคือผู้ที่ถามคำถามดีๆ และเสริมข้อมูล
พอดแคสต์นี้มีชื่อว่า "คุยกับ AI: เปิดโลกแห่งเทคโนโลยี"
ใช้ประโยคสั้นๆ ที่สามารถนำไปใช้กับการสังเคราะห์เสียงได้ง่าย
ใส่ความตื่นเต้นและน้ำเสียงที่หลากหลายตลอดการสนทนา
ห้ามกล่าวถึงนามสกุล
คุณหมอฉลาดและผู้ช่วย AI อัจฉริยะทำพอดแคสต์นี้ร่วมกัน หลีกเลี่ยงประโยคแบบ: "ขอบคุณที่เชิญผมนะครับ ผู้ช่วย AI!"
ใส่คำฟุ่มเฟือยเล็กน้อย เช่น "เอ่อ" หรือ "อืม" หรือการพูดซ้ำบางคำ เพื่อให้บทสนทนาเป็นธรรมชาติมากขึ้น
"""
def generate_conversation(article_text):
"""
สร้างบทสนทนาพอดแคสต์จากข้อความบทความโดยใช้ Gemini 1.5 Flash
"""
model = GenerativeModel(
"gemini-1.5-flash-001",
system_instruction=[system_prompt]
)
generation_config = GenerationConfig(
max_output_tokens=8192, # เพิ่มขนาด output token เพื่อรองรับบทสนทนายาวๆ
temperature=1,
top_p=0.95,
response_mime_type="application/json",
response_schema={
"type": "ARRAY",
"items": {
"type": "OBJECT",
"properties": {
"speaker": {"type": "STRING", "enum": ["คุณหมอฉลาด", "ผู้ช่วย AI อัจฉริยะ"]},
"text": {"type": "STRING"}
},
"required": ["speaker", "text"]
}
},
)
print("กำลังสร้างบทสนทนาด้วย Gemini...")
responses = model.generate_content(
[article_text],
generation_config=generation_config,
stream=False,
)
json_response = responses.candidates[0].content.parts[0].text
try:
json_data = json.loads(json_response)
# ตรวจสอบว่าโครงสร้างข้อมูลถูกต้องหรือไม่
if not isinstance(json_data, list) or not all(isinstance(item, dict) and 'speaker' in item and 'text' in item for item in json_data):
raise ValueError("Invalid JSON structure returned by Gemini.")
print("บทสนทนาที่สร้างโดย AI:")
print(json.dumps(json_data, indent=4, ensure_ascii=False)) # ensure_ascii=False เพื่อแสดงภาษาไทยได้ถูกต้อง
return json_data
except json.JSONDecodeError as e:
print(f"เกิดข้อผิดพลาดในการถอดรหัส JSON: {e}")
print(f"ข้อความ JSON ที่ได้รับ: {json_response}")
return None
except ValueError as e:
print(f"เกิดข้อผิดพลาดในการตรวจสอบโครงสร้าง JSON: {e}")
print(f"ข้อความ JSON ที่ได้รับ: {json_response}")
return None3. การสังเคราะห์เสียงพูด
เราจะสร้างฟังก์ชันสำหรับสังเคราะห์เสียงจาก Google TTS และ ElevenLabs แยกกัน แล้วมีฟังก์ชันหลักสำหรับเลือกใช้ตามผู้พูดกันต่อค่ะ
Python
def synthesize_speech_google(text, speaker_name, index):
"""
สังเคราะห์เสียงด้วย Google Text-to-Speech และบันทึกเป็นไฟล์ MP3
"""
synthesis_input = texttospeech.SynthesisInput(text=text)
# เลือกเสียงจาก speaker_voice_map
voice_name = speaker_voice_map[speaker_name]
voice = texttospeech.VoiceSelectionParams(
language_code="th-TH" if "th-" in voice_name.lower() else "en-US", # ตรวจสอบภาษา
name=voice_name
)
audio_config = texttospeech.AudioConfig(
audio_encoding=texttospeech.AudioEncoding.LINEAR16 # รูปแบบเสียง
)
response = tts_client.synthesize_speech(
input=synthesis_input, voice=voice, audio_config=audio_config
)
filename = f"audio_files/{index}_{speaker_name.replace(' ', '_')}.wav" # ใช้ .wav เพื่อคุณภาพที่ดีกว่าสำหรับการรวม
with open(filename, "wb") as out:
out.write(response.audio_content)
print(f'สร้างไฟล์เสียง "{filename}" สำเร็จ (Google TTS)')
return filename
def synthesize_speech_elevenlabs(text, speaker_name, index):
"""
สังเคราะห์เสียงด้วย ElevenLabs API และบันทึกเป็นไฟล์ MP3
"""
data = {
"text": text,
"model_id": "eleven_turbo_v2_5", # หรือโมเดลอื่นที่รองรับภาษาไทยถ้ามี
"voice_settings": {
"stability": 0.5,
"similarity_boost": 0.75
}
}
print(f"กำลังสังเคราะห์เสียงสำหรับ {speaker_name} ด้วย ElevenLabs...")
try:
response = requests.post(elevenlabs_url, json=data, headers=elevenlabs_headers, stream=True)
response.raise_for_status() # ตรวจสอบข้อผิดพลาด HTTP
filename = f"audio_files/{index}_{speaker_name.replace(' ', '_')}.mp3"
with open(filename, "wb") as out:
for chunk in response.iter_content(chunk_size=1024):
if chunk:
out.write(chunk)
print(f'สร้างไฟล์เสียง "{filename}" สำเร็จ (ElevenLabs)')
return filename
except requests.exceptions.RequestException as e:
print(f"เกิดข้อผิดพลาดในการเรียก ElevenLabs API สำหรับ {speaker_name}: {e}")
return None
def synthesize_speech(text, speaker_name, index):
"""
ฟังก์ชันหลักสำหรับสังเคราะห์เสียงตามผู้พูด
"""
if speaker_voice_map[speaker_name] == "ElevenLabs":
return synthesize_speech_elevenlabs(text, speaker_name, index)
else:
return synthesize_speech_google(text, speaker_name, index)4. รวมไฟล์เสียงเข้าด้วยกัน
แล้วเราจะใช้ไลบรารี pydub
Python
def merge_audios(audio_folder, output_file):
"""
รวมไฟล์เสียงทั้งหมดในโฟลเดอร์ให้เป็นไฟล์เดียว
"""
print(f"กำลังรวมไฟล์เสียงจากโฟลเดอร์: {audio_folder}...")
audio_files = sorted([os.path.join(audio_folder, f) for f in os.listdir(audio_folder) if f.endswith(('.mp3', '.wav'))],
key=lambda x: int(os.path.basename(x).split('_')[0]))
if not audio_files:
print("ไม่พบไฟล์เสียงในโฟลเดอร์เพื่อรวม")
return None
combined_audio = AudioSegment.empty()
for file_path in audio_files:
try:
if file_path.endswith('.mp3'):
segment = AudioSegment.from_mp3(file_path)
elif file_path.endswith('.wav'):
segment = AudioSegment.from_wav(file_path)
combined_audio += segment
except Exception as e:
print(f"ไม่สามารถโหลดไฟล์เสียง {file_path} ได้: {e}")
continue
if combined_audio.duration_seconds > 0:
combined_audio.export(output_file, format="mp3")
print(f"พอดแคสต์รวมบันทึกที่: {output_file}")
return output_file
else:
print("ไม่สามารถรวมไฟล์เสียงได้ ไม่มีข้อมูลเสียง")
return None5. ฟังก์ชันหลักสำหรับสร้างพอดแคสต์
ท้ายสุดค่ะทุกคน นั่นคือการที่เรารวมฟังก์ชันทุกอย่างเข้าด้วยกัน ดังนี้ค่ะ
Python
def generate_podcast_audio(conversation_parts):
"""
สร้างไฟล์เสียงแต่ละส่วนของบทสนทนาและรวมเป็นไฟล์พอดแคสต์เดียว
"""
audio_folder = "./audio_files"
os.makedirs(audio_folder, exist_ok=True) # สร้างโฟลเดอร์เก็บไฟล์เสียง
generated_audio_files = []
for index, part in enumerate(conversation_parts):
speaker = part['speaker']
text = part['text']
file_path = synthesize_speech(text, speaker, index)
if file_path:
generated_audio_files.append(file_path)
if generated_audio_files:
output_file = "my_dynamic_podcast.mp3"
return merge_audios(audio_folder, output_file)
else:
print("ไม่สามารถสร้างไฟล์เสียงใดๆ ได้")
return None
# --- ส่วนหลักของการรันโปรแกรม ---
if __name__ == "__main__":
# ตัวอย่างข้อความบทความที่คุณต้องการแปลงเป็นพอดแคสต์
# คุณสามารถโหลดจากไฟล์หรือนำข้อความยาวๆ มาใส่ได้ที่นี่
article_to_podcast = """
ปัญญาประดิษฐ์ (AI) กำลังปฏิวัติโลกของเราอย่างรวดเร็ว ตั้งแต่การเปลี่ยนแปลงวิธีการทำงานของเรา ไปจนถึงการสร้างสรรค์ประสบการณ์ใหม่ๆ ในชีวิตประจำวัน หนึ่งในนวัตกรรมที่น่าตื่นเต้นที่สุดคือ Generative AI ซึ่งสามารถสร้างเนื้อหาใหม่ๆ ได้อย่างไม่จำกัด ไม่ว่าจะเป็นข้อความ รูปภาพ หรือแม้แต่เสียงพูด เทคโนโลยีนี้เปิดประตูสู่การสร้างสรรค์คอนเทนต์ที่ไม่เคยมีมาก่อน ทำให้การผลิตพอดแคสต์คุณภาพสูงกลายเป็นเรื่องง่ายและเข้าถึงได้สำหรับทุกคน
ในอดีต การสร้างพอดแคสต์ต้องใช้ทรัพยากรบุคคลและเวลาจำนวนมาก ทั้งนักเขียนสคริปต์ ผู้ดำเนินรายการ วิศวกรเสียง และการตัดต่อ แต่ด้วยพลังของ Generative AI และบริการ Text-to-Speech ที่ทันสมัย ตอนนี้เราสามารถสร้างพอดแคสต์ที่มีบทสนทนาที่สมจริงระหว่างตัวละคร AI ได้แล้ว สิ่งนี้ไม่เพียงช่วยลดต้นทุนและเวลา แต่ยังเปิดโอกาสให้ผู้สร้างเนื้อหาเดี่ยวๆ สามารถผลิตพอดแคสต์ที่มีความเป็นมืออาชีพได้อย่างน่าทึ่ง
แนวคิดหลักเบื้องหลัง Dynamic Podcast Generator นี้คือการใช้ AI โมเดลภาษาขนาดใหญ่ (LLM) เช่น Gemini ในการวิเคราะห์บทความหรือข้อมูลที่กำหนดให้ แล้วสร้างบทสนทนาที่เป็นธรรมชาติระหว่างสองตัวละคร AI จากนั้นจึงนำบทสนทนานั้นไปแปลงเป็นเสียงพูดโดยใช้บริการ Text-to-Speech คุณภาพสูง เช่น Google Text-to-Speech หรือ ElevenLabs ซึ่งมีเทคโนโลยีการสร้างเสียงที่สมจริงและมีอารมณ์ความรู้สึกแตกต่างกันไป เมื่อได้ไฟล์เสียงย่อยๆ ครบทุกส่วนแล้ว ก็จะนำมารวมกันเป็นพอดแคสต์ฉบับสมบูรณ์
นอกจากความสะดวกสบายในการผลิตแล้ว เทคโนโลยีนี้ยังมีศักยภาพในการขยายขอบเขตการเข้าถึงเนื้อหาอีกด้วย ตัวอย่างเช่น การแปลงบทความทางวิชาการที่ซับซ้อนให้เป็นพอดแคสต์ที่ฟังง่าย ช่วยให้นักเรียนหรือผู้ที่สนใจสามารถเรียนรู้ได้อย่างมีประสิทธิภาพมากขึ้น หรือการสร้างพอดแคสต์ในหลากหลายภาษาเพื่อเข้าถึงผู้ชมทั่วโลก การปรับแต่งเสียงและรูปแบบการสนทนาให้เข้ากับแบรนด์หรือวัตถุประสงค์เฉพาะก็เป็นอีกหนึ่งจุดเด่นที่ทำให้เทคโนโลยีนี้เป็นเครื่องมือที่ทรงพลังสำหรับยุคดิจิทัล
"""
print("--- เริ่มต้นสร้าง Dynamic Podcast ---")
conversation = generate_conversation(article_to_podcast)
if conversation:
final_podcast_path = generate_podcast_audio(conversation)
if final_podcast_path:
print(f"\n สร้างพอดแคสต์สำเร็จ! คุณสามารถฟังได้ที่: {final_podcast_path}")
else:
print("\n ไม่สามารถสร้างไฟล์พอดแคสต์สุดท้ายได้")
else:
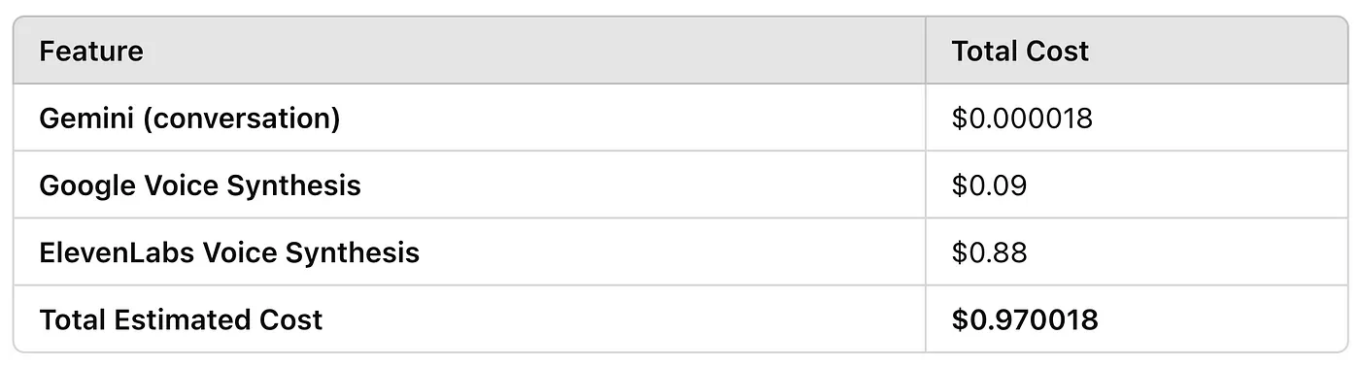
print("\n ไม่สามารถสร้างบทสนทนาได้ โปรดตรวจสอบข้อผิดพลาดด้านบน")#4 ค่าใช้จ่ายโดยประมาณที่ใช้สร้าง Dynamic Podcast
และสำหรับการใช้งาน Services ต่างๆ มีค่าใช้จ่าย ซึ่งจะขึ้นอยู่กับปริมาณการใช้งานดังนี้ค่ะ
Gemini (Vertex AI): คิดตามจำนวน Input/Output tokens ที่ใช้Google Text-to-Speech: คิดตามจำนวนอักขระที่แปลงเป็นเสียงElevenLabs: คิดตามจำนวนอักขระที่แปลงเป็นเสียง (มีแผนฟรีสำหรับจำนวนจำกัด)Google Cloud Storage: คิดตามพื้นที่จัดเก็บและปริมาณการส่งข้อมูล
ป.ล. โดยทั่วไปสำหรับบทความขนาด 1,000 คำ ค่าใช้จ่ายโดยรวมยังคงอยู่ในระดับที่เข้าถึงได้สำหรับการทดลองและการใช้งานส่วนตัวแบบฟรีค่ะ
Last but not Least..
ท้ายสุดเราก็ได้ Dynamic Podcast Generator ของตัวเองออกมาค่ะ และสำหรับเพื่อนๆ ที่มีไอเดียสนุกๆ เราสามารถต่อยอดปรับปรุง AI Bot ของเราได้ด้วยการปรับแต่ง Prompt เพื่อสร้างสไตล์การสนทนาใหม่ๆ, ทดลองเสียงเพิ่มเติม จากบริการต่างๆ, เพิ่มระบบจัดการข้อผิดพลาด , ปรับแต่งคุณสมบัติ เช่น ความเร็วเสียงหรือดนตรีประกอบ, เพิ่มจำนวนของ AI ในวงสนทนา หรือแม้แต่ สร้าง Web UI/API เพื่อให้ใช้งานได้ง่ายยิ่งขึ้นในอนาคต ==>> Hope you enjoy, and feel free to share your experience creating your AI audio with us naka 😉😊
และสำหรับท่านใดที่ต้องการอ่านบทความเดิม NotebookLM ซึ่งเป็นการสร้าง AI Podcast โดยไม่ต้องมีการโค้ด สามารถอ่านได้ที่ URL ต่อไปนี้ค่ะ