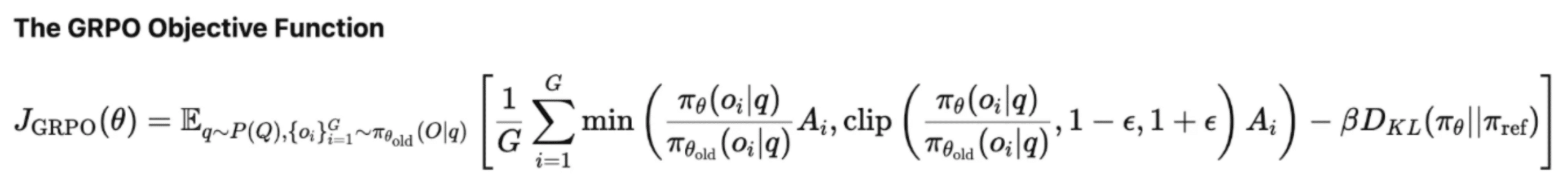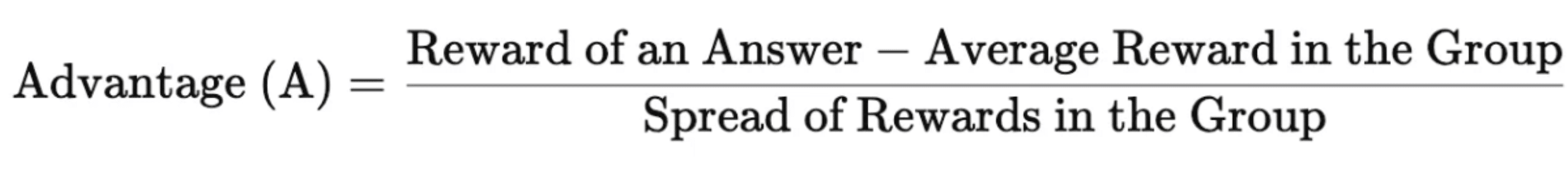สวัสดีค่ะทุกท่าน^^ บทความนี้นิกจะพาทุกท่านไปเจาะลึกถึงคณิตศาสตร์เบื้องหลัง DeepSeek ในการทำ Optimization ด้วยเทคนิคที่ชื่อว่า Group Relative Policy Optimization หรือ “GRPO” ซึ่งเป็น Machine learning (ML) Algorithm แบบ Reinforcement Learning ซึ่งเป็นตัวขับเคลื่อนความสามารถในการใช้เหตุผลอันยอดเยี่ยมของ DeepSeek โดยความเข้าใจนี้จะทำให้เราสามารถเข้าใจถึงบริบทของการใช้งานมากขึ้น โดยเฉพาะอย่างยิ่งสำหรับผู้ที่ต้องการพัฒนาต่อ หรือแม้แต่ Marketer และ Data Analyst ที่ต้องการใช้ Service นี้ในการวิเคราะห์ข้อมูล พัฒนาแผนการตลาด และงานด้านการ Support ลูกค้าค่ะ
โดยเนื้อหาของบทความจะอธิบายให้เห็นว่า GRPO ทำงานอย่างไร? องค์ประกอบสำคัญของ GRPO มีอะไรบ้าง? และทำไมโมเดลแบบนี้ถึงเข้ามาเป็น Game changer สำหรับการ Train โมเดลภาษาขนาดใหญ่ที่เราเรียกกันว่า Large Language Models (LLM) (ノ◕ヮ◕)ノ*:・゚✧
Group Relative Policy Optimisation (GRPO) คืออะไร?
Group Relative Policy Optimisation เป็น Algorithm การเรียนรู้แบบเสริมแรง (Reinforcement Learning: RL) ที่ออกแบบมาโดยเฉพาะเพื่อเสริมความสามารถในการใช้เหตุผลของโมเดลภาษาขนาดใหญ่ (Large Language Models: LLM) ซึ่งต่างจากวิธี Reinforcement ทั่วไปที่ต้องอาศัยผู้ประเมินภายนอกที่เรียกว่า “Critics” จำนวนมากในการ Guide ตัวโมเดล แต่!! Group Relative Policy Optimisation หรือ “GRPO” จะปรับให้โมเดลเหมาะสมที่สุดโดยใช้การประเมินกลุ่มคำตอบที่สัมพันธ์กัน ^^
ซึ่งวิธี GRPO จะช่วยให้การ Trian โมเดลมีประสิทธิภาพมากขึ้น และด้วยเหตุผลนี้เองค่ะที่ทำให้ GRPO เหมาะอย่างยิ่งสำหรับงานในประเภทการใช้เหตุผลที่ต้องใช้การแก้ปัญหาที่ซับซ้อน และการเชื่อมโยงข้อมูลในรูปแบบที่ต่อเนื่องหลาย Prompts ซึ่งเรารู้จักกันดีในชื่อว่าการทำ “Chain of Thought “
ในขณะที่วิธี Reinforcement Learning หรือ RL แบบดั้งเดิม เช่น Proximal Policy Optimization (PPO) มีจุด Challenge ที่สำคัญคือ
เมื่อเรานำ LLMs ที่มีอัลกอริทึมเป็น PPO ไปใช้กับงานในลักษณะของการใช้เหตุผลนั้น PPO ต้องใช้ Critic Model แยกต่างหาก เพื่อประมาณค่าของการตอบสนองแต่ละครั้ง ซึ่งสิ่งนี้เองที่ทำให้หน่วยความจำและความต้องการในการคำนวณเพิ่มขึ้นเป็นสองเท่า!!!! อีกทั้งการฝึก Critic Model นั้นซับซ้อนและมีแนวโน้มที่จะเกิดข้อผิดพลาดได้ โดยเฉพาะสำหรับงานที่มีการประเมินแบบอัตนัยหรือแบบละเอียดอ่อน
ใน Reinforcement Learning Pipeline ต้องการทรัพยากรในการคำนวณจำนวนมากกกกก (มากจริงๆ ค่ะ) เพื่อประเมินและเพิ่มประสิทธิภาพการตอบสนองแบบซ้ำๆ ซึ่งการปรับขนาดวิธีการเหล่านี้ให้ใหญ่ขึ้นใน LLMs ใดๆ ก็ตามจะทำให้ต้นทุนพุ่งสูงขึ้น
อาจพบปัญหาในการทำ Scaleble ใน RL แบบดั้งเดิม ซึ่งปัญหานี้มาจากการประเมินความสามารถของ Model ด้วยการให้ Reward ในกรณีของการทำงานที่หลากหลายซึ่งยากต่อการสรุปผลในโดเมนของการใช้เหตุผล
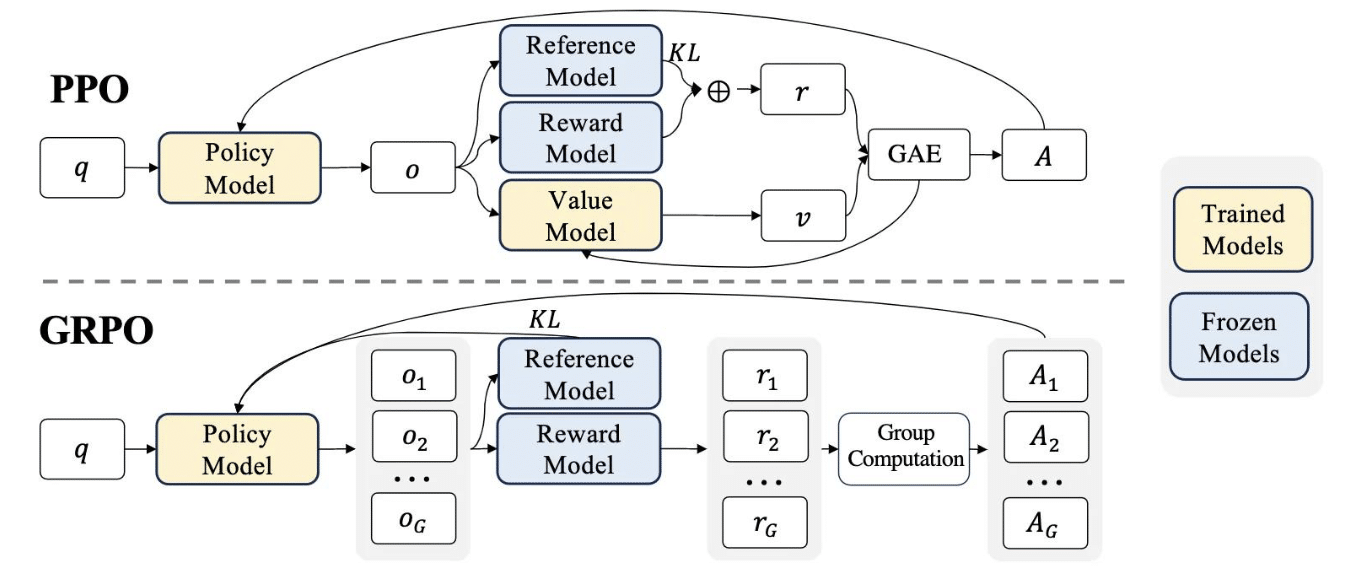
Demonstration of PPO and our GRPO. GRPO foregoes the value model, insteadhttps://community.aws/ )
โดย GRPO ของ DeepSeek สามารถแก้ปัญหาเหล่านี้ได้ด้วย (o゜▽゜)o☆
การทำ “Critic-free optimisation ” หรือการตัดส่วนของผู้ประเมินภายนอกออก ทำให้ GRPO ไม่จำเป็นต้องใช้ Critic model แต่ใช้เป็นการเปรียบเทียบคำตอบภายในกลุ่ม ซึ่งสิ่งนี้เองค่ะที่ช่วยลดภาระงานในการคำนวณได้อย่างมาก
ใช้การประเมินแบบสัมพันธ์ คือแทนที่จะพึ่งพาผู้ประเมินภายนอก แต่ GRPO จะใช้พลวัตของกลุ่มเพื่อประเมินว่าคำตอบหนึ่งมีประสิทธิภาพดีเพียงใดเมื่อเทียบกับคำตอบอื่นๆ ในชุดเดียวกัน
ด้วยการทำ Group-based advantages ทำให้ GRPO สามารถลดความซับซ้อนของกระบวนการประเมิน Reward ทำให้เร็วขึ้นและ Scalable ได้ง่ายขึ้นสำหรับแบบจำลองขนาดใหญ่
ดังนั้นหัวใจสำคัญของ GRPO คือแนวคิดของการประเมินแบบสัมพันธ์ (Relative evaluation ) สำหรับแต่ละ Input query โดยโมเดลจะสร้างกลุ่มของคำตอบที่เป็นไปได้ ซึ่งคำตอบเหล่านั้นจะได้รับคะแนนตามการเปรียบเทียบคำตอบกับคำตอบอื่นๆ ในกลุ่ม แทนที่จะประเมินแบบแยกกัน และ Advantage ของคำตอบจะสะท้อนให้เห็นว่าคำตอบนั้นดีกว่าหรือแย่กว่าประสิทธิภาพโดยเฉลี่ยของกลุ่มมากเพียงใด ซึ่งด้วยแนวทางนี้เองที่ทำให้ไม่จำเป็นต้องใช้ผู้ประเมินภายนอกแยกต่างหาก
GRPO จึงมีประสิทธิภาพมากยิ่งขึ้น และด้วยการส่งเสริมการแข่งขันภายในกลุ่มของ GRPO ทำให้โมเดลได้ปรับปรุงความสามารถในการใช้เหตุผลอย่างสม่ำเสมอ ทำให้ GRPO ซึ่งเป็น Algorithm ที่อยู่เบื้องหลัง DeepSeek สามารถให้ผลลัพธ์ที่ดีในงานด้านการใช้เหตุผลได้
คณิตศาสตร์ของ GRPO optimisation ของ DeepSeek
เริ่มแรกเรามาทำความเข้าใจในฟังก์ชันวัตถุประสงค์ของ GRPO กันค่ะObjective Function หรือ ฟังก์ชันวัตถุประสงค์ คือฟังก์ชัน/สมการทางคณิตศาสตร์ที่ใช้กำหนดเป้าหมายของปัญหา (สำหรับเพื่อนๆ ที่ต้องการทำความเข้าในเพิ่มเติมเรื่องการทำ Optimisation/Optimization สามารถเข้าไปอ่านกันได้ที่บทความนี้นะคะ : https://everydaymarketing.co/knowledge/optimization-101-for-marketing-linear-programming/
โดยฟังก์ชันวัตถุประสงค์ใน GRPO จะกำหนดว่าโมเดลเรียนรู้ที่จะปรับปรุง “Policy ” ซึ่งเป็นตัวกำหนดว่า Agent ของเราจะทำงานอย่างไร เพื่อขับเคลื่อนความสามารถในการสร้างการตอบสนองที่มีคุณภาพสูง ซึ่งมีรายละเอียดดังนี้ค่ะ
จากสมการด้านบน อธิบายได้ดังนี้
#1 เริ่มต้นด้วย Query : (q ) จาก Training Data: P(Q)
ยกตัวอย่างเพื่อให้เห็นภาพให้ทุกท่านคิดตามดังนี้นะคะ “สมมติว่าเรามีคำถามคือ “ผลรวมของ 1 + 7 คืออะไร?”
#2 ขั้นตอนที่ 2 คือการสร้างกลุ่มคำตอบ (Oi ) :
o1: “คำตอบคือ 8”
o2: “แปด”
o3: “เป็น 12”
o4: “ผลรวมคือ 8”
*ทุกท่านสังเกตเห็นอะไรไหมคะ? ด้วยความที่ Generative AI อย่าง Deepseek ไม่ใช่เครื่องคิดเลข เพราะฉะนั้นคำตอบที่ได้ ก็จะไม่ได้เป็นตัวเลขแบบ Number แต่จะมี Wording ของคำตอบมาด้วยตาม Probability ที่เกี่ยวเนื่อง
#3 คำนวณ Reward สำหรับคำตอบ (Response) แต่ละข้อ : รางวัล ” คือแนวทางการเรียนรู้ของโมเดลโดยการวัดคุณภาพของคำตอบ ซึ่งประเภทของ Reward ใน GRPO มีดังนี้ค่ะ
Accuracy Rewards: ขึ้นอยู่กับความถูกต้องของคำตอบ (เช่น สำหรับการแก้ปัญหาคณิตศาสตร์เป็นการตรวจสอบว่าคำตอบนั้นถูกต้องหรือไม่) Format Rewards: ขึ้นอยู่กับลักษณะของคำตอบนั้นว่าสอดคล้องกับหลักเกณฑ์โครงสร้างหรือรูปแบบที่เหมาะสมหรือไม่ Language Consistency Rewards หรือ รางวัลความสอดคล้องของภาษา ส่วนนี้จะพิจารณาที่การใช้ภาษาที่ผสมกันหรือการจัดรูปแบบที่ไม่สอดคล้องกัน
โดยโมเดลจะกำหนด Reward (ri)
r1=1.0 (ถูกต้องและจัดรูปแบบดี)
r2=0.7 (ถูกต้องแต่ไม่เป็นทางการ)
r3=0.0 (คำตอบไม่ถูกต้อง)
r4=1.0 (ถูกต้องและจัดรูปแบบดี)
#4 เปรียบเทียบแต่ละ Response ในรูปแบบกลุ่ม : (Ai)
โดย GRPO จะสร้าง Response หลายรายการสำหรับตอบคำถามในแต่ละ Prompt และใช้ค่า Average reward ของกลุ่มเป็น Baseline ซึ่งสามารถเข้าใจได้ง่ายขึ้นผ่านด้วยสมการด้านล่างนี้ค่ะ
ซึ่งกรณีค่า A A “ o1
#6 KL Divergence Integration:
โดย GRPO จะรวมผลรวมค่าความแตกต่างของ KL (สำหรับ KL ให้กลับขึ้นไปดูแผนภาพของโมเดลทั้ง PPO และ GRPO ด้านบนของบทความนะคะ) ระหว่าง Policy ปัจจุบันและ Policy อ้างอิง (มักจะเป็นแบบจำลอง SFT) ลงใน Loss function โดยตรง
ซึ่งวิธีการแบบ Group Relative ที่ GRPO ของ DeepSeek ที่ใช้ประโยชน์ในการคำนวณ Adventages (A)
สรุปการทำงานของ GRPO คือการสร้างกลุ่มคำตอบสำหรับการค้นหา คำนวณ Rewards สำหรับคำตอบแต่ละข้อโดยอิงตามเกณฑ์ที่กำหนดไว้ล่วงหน้า (เช่น ความแม่นยำ รูปแบบ) แล้วเปรียบเทียบคำตอบภายในกลุ่มเพื่อคำนวณ Relative Adventages (Ai Ai
Last but not Least..
ท้ายสุด,, นิกเชื่อว่าทุกท่านที่ร่วมเดินทางกันมาจนถึงส่วนสุดท้ายของบทความนี้ น่าจะได้ประโยชน์และเข้าใจถึง Concept โดยภาพรวมของคณิตศาสตร์และ Optimisation โมเดลที่อยู่เบื้องหลังการทำงานอย่งมีประสิทธิภาพของ DeepSeek กันมากยิ่งขึ้น ทั้งในส่วนของ Data Analyst ผู้สนใจศึกษาด้านนี้ โดยเฉพาะอย่างยิ่งชาว Marketer ในยุคแห่ง Generative AI ที่การเป็นแค่ User ธรรมดาๆ ไม่เพียงพออีกต่อไปแล้ว แต่เรายังต้องเข้าใจถึงโครงสร้างการทำงานที่อยู่เบื้องหลัง AI ที่เราใช้อีกด้วยค่ะ^^
—Put the right GenAI(s) into the right job —
และสำหรับเพื่อนๆ ที่ต้องการข้อมูลเรื่องการเปรียบเทียบการใช้งานระหว่าง DeepSeek และ ChatGPT สามารถ ติดตามอ่านได้ที่บทความนี้ค่ะ =>>