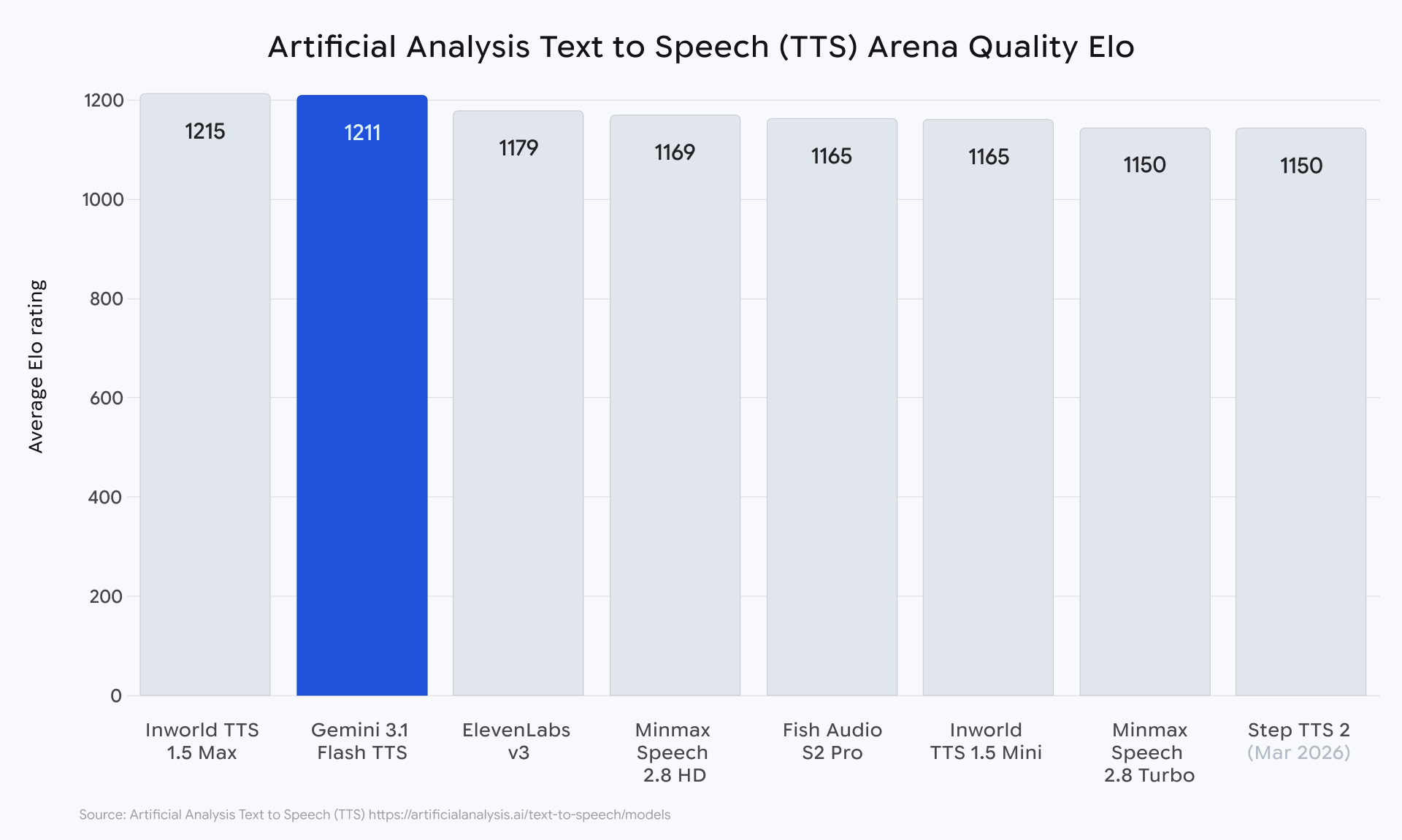
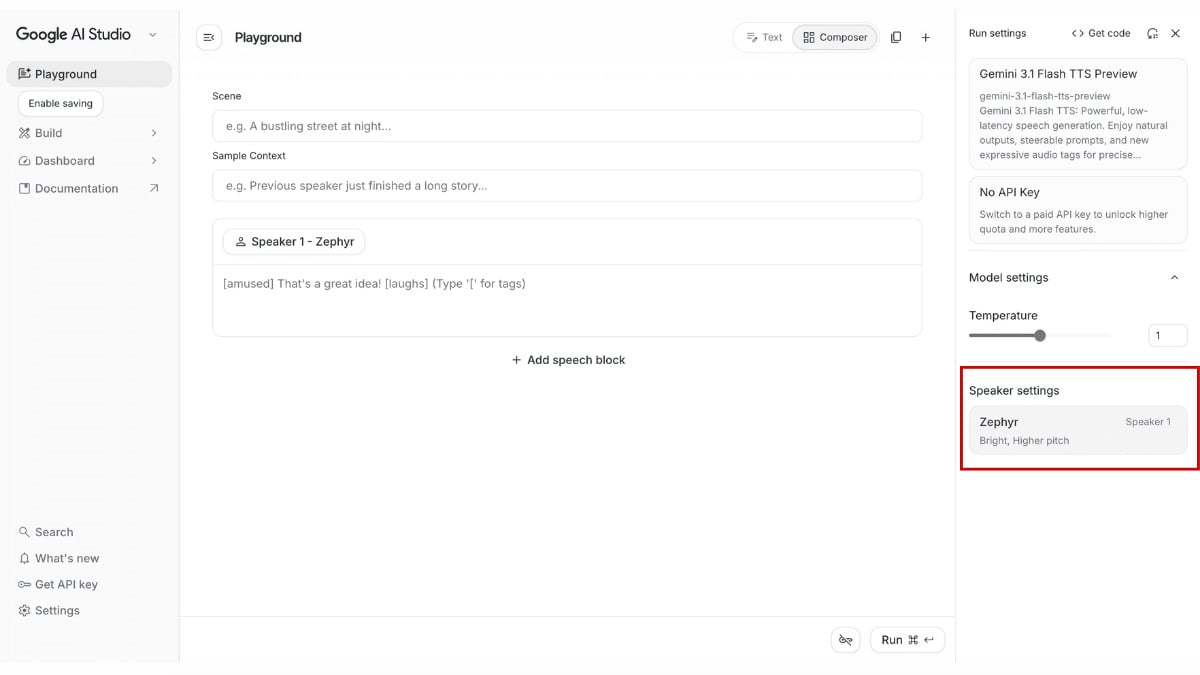
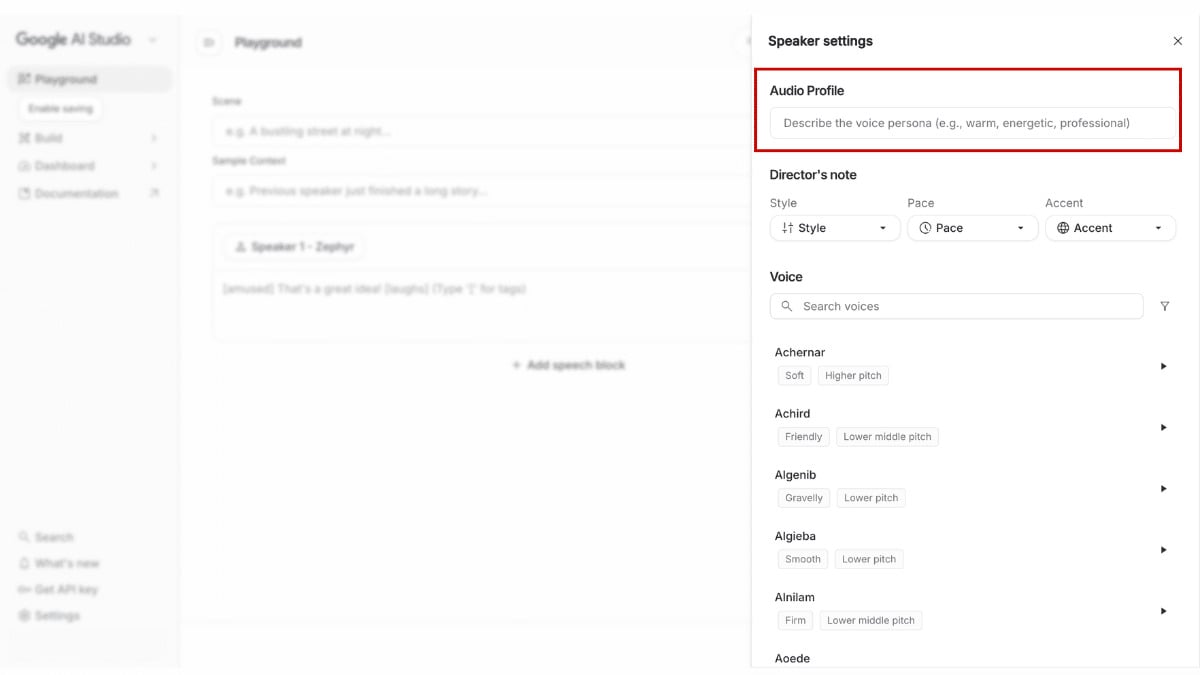
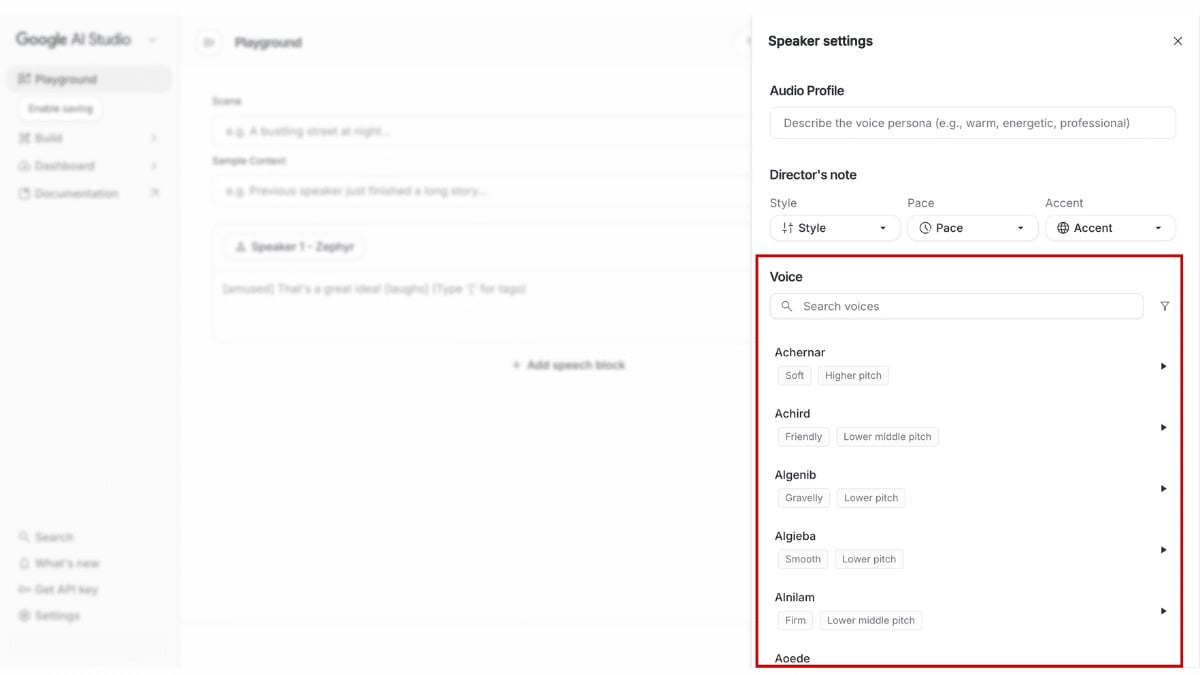
Gemini 3.1 Flash TTS คืออะไร และ Google กำลังอัปเดตอะไรอยู่
Google อธิบายว่า Gemini 3.1 Flash TTS คือโมเดล Text-to-Speech รุ่นใหม่ที่เน้นทั้งคุณภาพเสียง ความ expressive และความสามารถในการควบคุมเสียงอย่างละเอียด โดยเริ่มเปิดให้ใช้งานแบบ preview สำหรับนักพัฒนาผ่าน Gemini API และ Google AI Studio สำหรับฝั่งองค์กรบน Vertex AI และสำหรับผู้ใช้ Workspace ผ่าน Google Vids ด้วยเช่นกัน
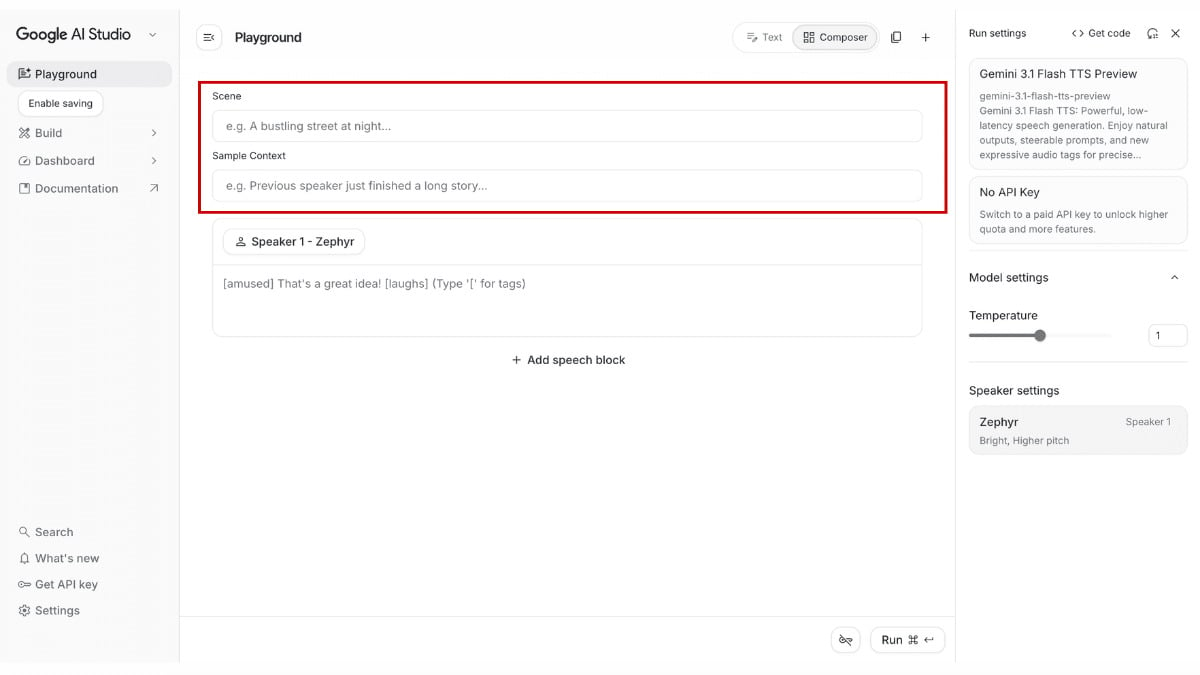
นี่จึงไม่ได้เป็นแค่ความสะดวกของหน้าตาโปรแกรม แต่คือสัญญาณว่าการสร้างบทพูดแบบสองคน สามคน หรือมากกว่านั้น กำลังกลายเป็น use case หลักของเครื่องมือนี้ครับ
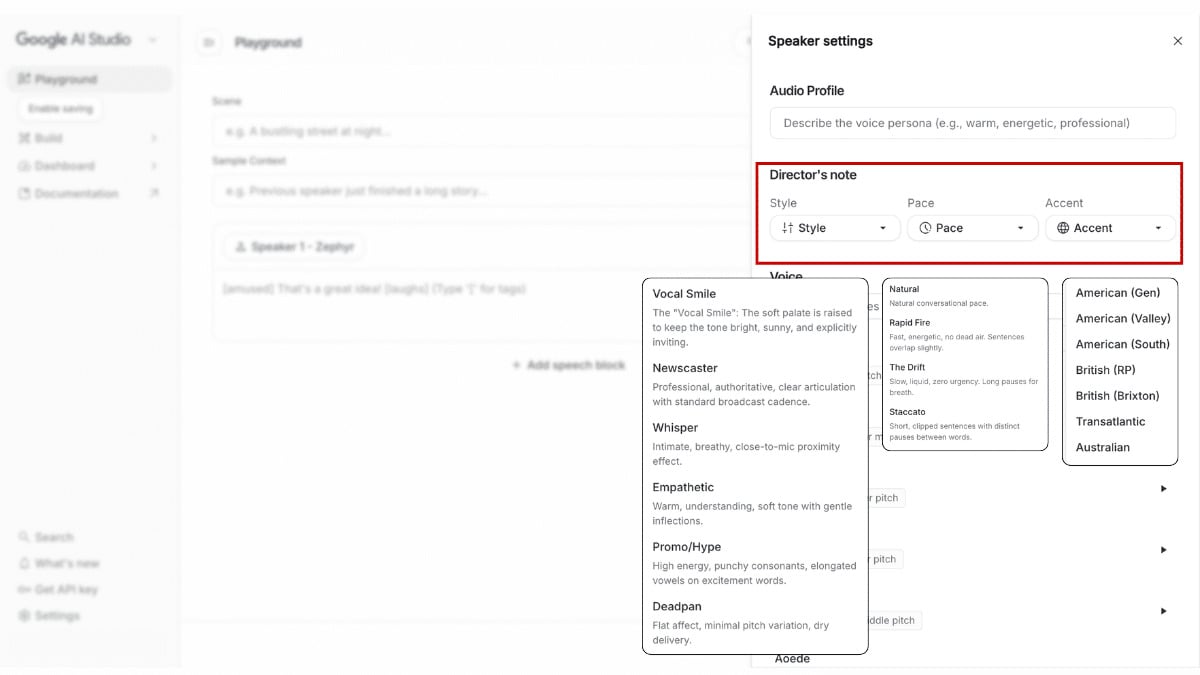
Pace จังหวะของการพูด ตัวเลือกในหมวด Pace เช่น Natural, Rapid Fire, The Drift และ Staccato บอกชัดว่า Google เข้าใจว่าความเร็วในการพูดไม่ใช่แค่เรื่องฟังทันหรือไม่ทัน แต่เป็นเรื่องอารมณ์ของคอนเทนต์ด้วย
Rapid Fire อาจเหมาะกับงานขาย งานเล่าอย่างมีพลัง หรือคลิปสั้นที่ต้องดึงความสนใจเร็ว ส่วน The Drift ซึ่งอธิบายว่าไหลช้า มีลมหายใจ มี pause ยาว ดูจะเหมาะกับงานเล่าเรื่อง งานสะท้อนความคิด หรือ content ที่ต้องการพื้นที่ทางอารมณ์มากกว่าครับ
Accent เปลี่ยนจากการเลือกภาษามาเป็นการเลือก positioning ของเสียง ในหมวด Accent มีตัวเลือกอย่าง American แบบทั่วไป American Valley American South, British RP, British Brixton, Transatlantic และ Australian สิ่งนี้น่าสนใจเพราะมันทำให้การเลือกสำเนียงไม่ใช่แค่เรื่องความถูกต้องทางภาษา แต่เป็นเรื่อง brand image และ audience fit ไปด้วย
สำหรับบางแบรนด์ สำเนียงแบบ British RP อาจทำให้ภาพลักษณ์ดูพรีเมียมขึ้น ขณะที่ American Gen อาจเข้าถึงคนหมู่มากง่ายกว่า ส่วนบาง use case อย่าง character-based content หรือ branded storytelling ก็อาจใช้สำเนียงเป็นส่วนหนึ่งของการสร้างบุคลิกของตัวละครได้เลย
นี่เป็นจุดที่คนทำคอนเทนต์น่าจะเห็นภาพชัดที่สุดว่า AI เสียงเริ่มเข้าใกล้การเป็นเครื่องมือกำกับ performance แล้วจริง ๆ ครับ
ถ้าจะสรุปให้เห็นภาพง่ายที่สุด ฝั่งกลางคือ Script + Context ฝั่งขวาคือ Direction + Performance และสิ่งที่เกิดขึ้นคือ คุณไม่ได้ใช้ AI เพื่ออ่านออกเสียง แต่กำลังใช้ AI เพื่อแสดงผ่านเสียง และนั่นคือเหตุผลว่าทำไมเครื่องมือนี้ถึงใกล้คำว่า creative direction มากขึ้นทุกที
สำหรับนักการตลาด มันเปิดทางให้แคมเปญเดียวกันมีหลายโทนเสียงได้ง่ายขึ้น เช่น เวอร์ชันขาย เวอร์ชันอธิบาย เวอร์ชันอบอุ่น หรือเวอร์ชันดึงอารมณ์ โดยไม่ต้องผ่านกระบวนการ production เต็มรูปแบบทุกครั้ง สำหรับนักพัฒนาและธุรกิจ มันไปได้ไกลกว่างานโฆษณา เพราะสามารถใช้สร้างเสียงสำหรับ AI agents, training content, customer communication, onboarding, explainers หรือแม้แต่ระบบโต้ตอบที่ต้องการบุคลิกเสียงเฉพาะตัวได้
ขอบคุณภาพจาก Shutterstock AI Generator a cinematic scene of a content creator sitting in front of a computer, controlling AI-generated voice like a film director, holographic sound waves and voice controls floating in the air, UI panels showing speech blocks, audio tags, and voice settings, glowing blue and purple neon tones, futuristic workspace, minimal but premium, soft lighting, depth of field, ultra realistic, high detail, 16:9 composition
ถ้ามองภาพกว้างกว่านั้น การเปิดตัว Gemini 3.1 Flash TTS ทำให้เห็นชัดว่า Google กำลังวาง AI ecosystem ให้ครอบคลุมงานสร้างสรรค์มากขึ้นเรื่อย ๆ ทั้งข้อความ ภาพ วิดีโอ และเสียง โดยบทความเปิดตัวก็ระบุชัดว่าระบบนี้เชื่อมไปถึง AI Studio, Vertex AI และ Google Vids แล้ว
นั่นแปลว่าในอนาคตอันใกล้ การสร้าง asset สำหรับคอนเทนต์อาจไม่ใช่กระบวนการแยกส่วนอีกต่อไป แต่กลายเป็น workflow เดียวที่ข้อความ ภาพ วิดีโอ และเสียงทำงานร่วมกันได้มากขึ้น ซึ่งสำหรับนักการตลาดและครีเอเตอร์ นี่คือการเปลี่ยนจากใช้ AI เป็นตัวช่วยทีละจุด ไปสู่การใช้ AI เป็นระบบผลิตงานทั้งสายครับ
อีกประเด็นที่ Google เน้นคือเสียงทั้งหมดที่สร้างจาก Gemini 3.1 Flash TTS จะถูก watermark ด้วย SynthID ซึ่งเป็น watermark ที่แทรกอยู่ในตัวเสียงเพื่อให้สามารถตรวจจับได้ในภายหลัง เป้าหมายคือช่วยลดความเสี่ยงด้าน misinformation และการใช้เสียง AI ในทางที่ทำให้ผู้ฟังเข้าใจผิดว่าเป็นเสียงมนุษย์จริง
ถ้าจะสรุปให้สั้นที่สุด Gemini 3.1 Flash TTS ไม่ได้เปลี่ยนแค่คำว่า Text-to-Speech แต่กำลังเปลี่ยนคำถามใหม่ทั้งหมด จากเดิมที่ถามว่า AI พูดได้เหมือนคนหรือยัง ไปเป็นเราสั่งให้ AI พูดแบบที่เราต้องการได้ละเอียดแค่ไหนแล้ว
และเมื่อคำถามเปลี่ยน ทักษะที่สำคัญก็เปลี่ยนตามไปด้วย ในโลกใหม่ของเครื่องมือแบบนี้ คนที่ได้เปรียบอาจไม่ใช่คนที่มีเสียงตัวเองดีที่สุด ไม่ใช่คนที่มีสตูดิโอใหญ่ที่สุด แต่อาจเป็นคนที่เข้าใจ mood เข้าใจ scene เข้าใจ persona และรู้ว่าจะกำกับจังหวะของคำพูดอย่างไรให้ตรงกับเป้าหมายของงาน
พูดอีกแบบคือ ยุคของ AI เสียงอาจไม่ได้ลดคุณค่าของความคิดสร้างสรรค์ลงเลย แต่มันกำลังย้ายคุณค่าจากการเปล่งเสียง ไปสู่การออกแบบเสียงแทน สุดท้ายแล้ว สิ่งที่น่าสนใจที่สุดอาจไม่ใช่แค่ว่า AI พูดได้สมจริงขึ้นแค่ไหน แต่อยู่ที่ว่าจากนี้ไป คนทำคอนเทนต์ นักการตลาด และธุรกิจ จะเริ่มใช้เสียงเป็นภาษาทางกลยุทธ์ได้ลึกขึ้นแค่ไหนต่างหาก ทุกวันนี้เทคโนโลยีพัฒนาขึ้นไปทุกวัน ถ้าใช้ให้ดีก็จะเกิดประโยชน์ แต่ถ้าใช้ผิดทางก็จะเกิดโทษครับ
ผมหวังว่าทุกคนจะนำการพัฒนาของเทคโนโลยีและบทความนี้ไปใช้ให้เกิดประโยชน์ ไม่มากก็น้อยนะครับ ฝากติดตามบทความด้านการใช้ AI แบบนี้ด้วยนะครับ หรือใครอยากให้นำ AI ตัวไหนมาเล่าให้ฟัง สามารถคอมเมนต์บอกกันได้เลยครับ
สำหรับนักอ่านที่ชอบ และ อยากอ่านบทความเกี่ยวกับการตลาด, Data และ AI เพิ่มเติม สามารถติดตามได้จาก เพจการตลาดวันละตอน รวมไปถึง Twitter Instagram YouTube ของการตลาดวันละตอนได้เลยนะครับ แล้วพบกันใหม่ในบทความหน้าครับ