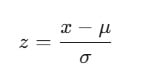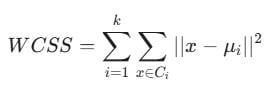สวัสดีค่ะทุกคน,, เมื่อสัปดาห์ที่แล้วมีคำถามจากผู้อ่านเรื่องการแบ่งกลุ่มลูกค้าต่อเนื่องจากเนื้อหาในบทความ: ML model(s) หรือ RFM: Customer Segmentation ข้อมูลนี้ใช้โมเดลอะไรดี? เข้ามาว่าในเชิงปฏิบัติสำหรับข้อมูลจริงนั้น Data Analyst และ Marketer ทำการวิเคราะห์ข้อมูลกันอย่างไรตั้งแต่ต้นจนจบ ซึ่งเนื้อหาในบทความก่อนหน้าเป็นการทำความเข้าใจความแตกต่างระหว่างการทำ Segmentation ด้วย RFM Model และทำ K-Mean Clustering ด้วย ML Algorithml ค่ะ
ในบทความนี้นิกเลยจะพาเพื่อนๆ มาเปลี่ยนทฤษฎีให้เป็นภาคปฏิบัติ โดยการชวนทุกท่านมาเขียนโค้ดทำ Customer Segmentation ด้วยเทคนิค K-Means Clustering โดยเราจะใช้ข้อมูลจากชุดข้อมูล Online Retail โดยเพิ่มความพิเศษเข้าไปคือเราจะไม่ทิ้ง Concept ของ RFM แต่เราจะนำตัวแปร Recency, Frequency และ Monetary นี่แหละค่ะ มาเป็น Features ป้อนเข้าสู่กระบวนการ Machine Learning ของเราค่ะ
Let’s go,,, เปิด Jupyter Notebook หรือ Colab ของทุกคนขึ้นมา หรือเปิด Colab ที่นิกทำไว้ให้เป็นตัวอย่าง แล้วมาลุยไปพร้อมกันเลยค่ะ (☞゚ヮ゚)☞
ชุดข้อมูล: Online Retail | อัลกอริทึม: K-Means + DBSCAN
- โหลดและทำความเข้าใจข้อมูล
- Cleansing Data
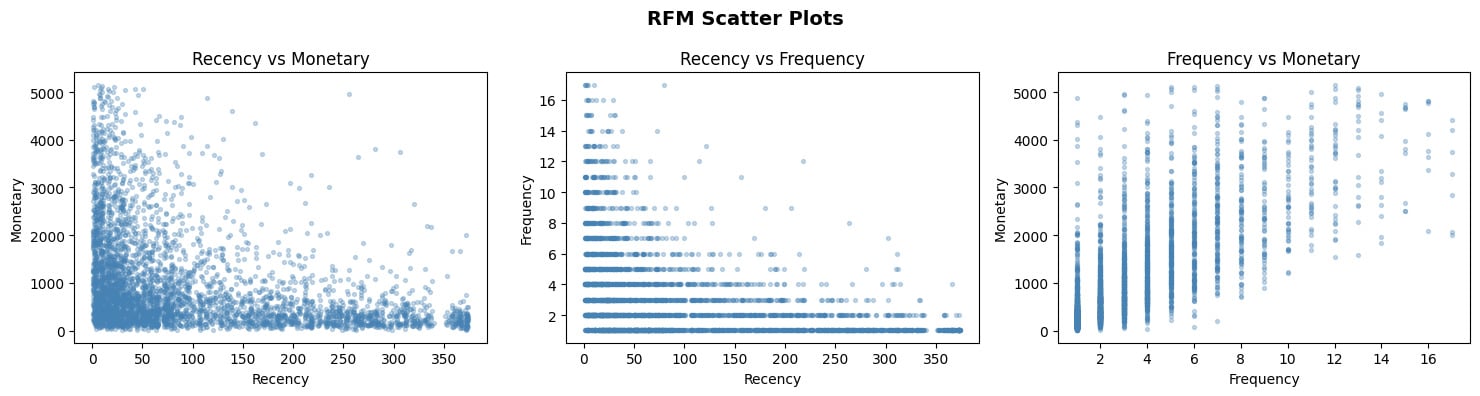
- สำรวจข้อมูลด้วยแผนภูมิ (EDA) และทำ Feature ใหม่ด้วย RFM
- ค้นหาจำนวนกลุ่มที่เหมาะสมที่สุด (Elbow Method)
- เริ่มการแบ่งกลุ่มด้วย K-Means clustering
- แสดงภาพผลลัพธ์ของกลุ่มต่างๆ
- ทดลองใช้อัลกอริทึมอื่น: DBSCAN
- วัดคุณภาพของการแบ่งกลุ่ม (Silhouette Score)
- ทำความเข้าใจความหมายของแต่ละกลุ่ม
Step 0-1: โหลดและทำความเข้าใจข้อมูล (Data Loading) 📂
ในขั้นตอนแรกของการทำ Data Science คือการโหลดข้อมูลเข้ามาดูหน้าตากันก่อนค่ะ ว่าข้อมูลที่เรามีพร้อมใช้งานแค่ไหน มีหน้าตาเป็นอย่างไร พร้อมกับการนำเข้า Lib ที่จำเป็นค่ะ
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.cluster import KMeans
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import silhouette_score
# โหลดชุดข้อมูล Online Retail
# ใครใช้ Colab อย่าลืมอัปโหลดไฟล์เข้าไปก่อนนะคะ^^
df = pd.read_excel(‘Online Retail.xlsx’)
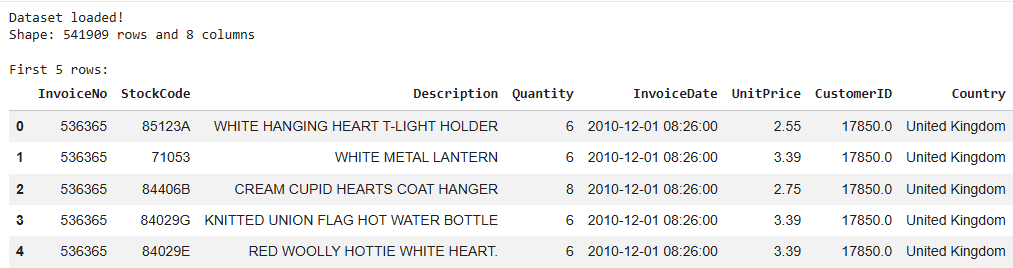
print(f”จำนวนข้อมูลทั้งหมด: {df.shape[0]} แถว, {df.shape[1]} คอลัมน์”)
df.head()
โดยในส่วนนี้เราได้ทำการ Import เครื่องมือที่จำเป็นเข้ามา ได้แก่ pandas เอาไว้จัดการตารางข้อมูล และ sklearn มาใช้งานในส่วน Machine Learning ค่ะ ซึ่งพอโหลดไฟล์เสร็จ คำสั่ง df.head() จะแสดงข้อมูล 5 บรรทัดแรกให้เราตรวจสอบว่า ข้อมูลมาครบถ้วนแล้วหรือไม่ค่ะ
Step 2: การเตรียมข้อมูลและสร้างตัวแปร RFM (Data Preprocessing & Feature Engineering) 🛠️
# 1. ทำความสะอาดข้อมูล: ลบแถวที่ไม่มี CustomerID และเอาเฉพาะยอดซื้อที่มากกว่า 0
df = df.dropna(subset=[‘CustomerID’])
df = df[df[‘Quantity’] > 0]
# 2. คำนวณยอดเงินรวมแต่ละ Transaction (Quantity * UnitPrice)
df[‘TotalSales’] = df[‘Quantity’] * df[‘UnitPrice’]
# 3. กำหนดวัน ‘ปัจจุบัน’ (ดึงวันล่าสุดในข้อมูล + 1 วัน) เพื่อใช้หา Recency
import datetime as dt
current_date = df[‘InvoiceDate’].max() + dt.timedelta(days=1)
# 4. สร้างตัวแปร R, F, M สำหรับลูกค้าแต่ละราย
rfm = df.groupby(‘CustomerID’).agg({
‘InvoiceDate’: lambda x: (current_date – x.max()).days, # Recency
‘InvoiceNo’: ‘count’, # Frequency
‘TotalSales’: ‘sum’ # Monetary}).reset_index()
# เปลี่ยนชื่อคอลัมน์ให้ดูง่ายขึ้น
rfm.columns = [‘CustomerID’, ‘Recency’, ‘Frequency’, ‘Monetary’]
rfm.head()
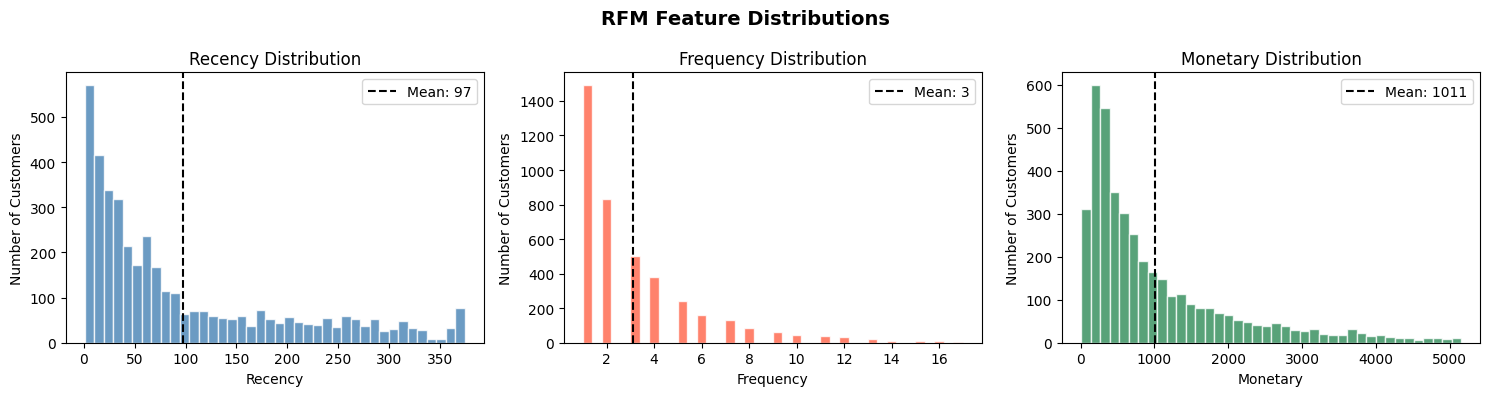
อย่างที่นิกเคยเล่าให้อ่านกันในบทความที่แล้วค่ะว่า ในการทำ ML Algorithm เพื่อให้ได้ AI Model ใดๆ ออกมา ความถูกต้องของข้อมูลมีความสำคัญมากๆ เพราะ Garbage in, garbage out ค่ะ ดังนั้นจากข้อมูลดิบที่เราได้มา จะต้องมาตรวจสอบหาค่าว่างหรือ Missing values และข้อมูลที่ผิดพลาด หรือเป็นไปไม่ได้อื่นๆ เช่น ยอดสั่งซื้อติดลบ (โดนคืนของ) ซึ่งเราต้องจัดการตรงนี้ก่อน แล้วค่อยแปลงให้อยู่ในรูปของ RFM Score ของลูกค้าแต่ละคนค่ะ
โค้ดส่วนนี้ เราทำการ Group ข้อมูลด้วย CustomerID ค่ะ เพื่อให้รู้ว่านาย A หรือนาย B มีพฤติกรรมอย่างไรบ้าง
- Recency: วันปัจจุบัน ลบกับ วันที่เขามาซื้อของครั้งล่าสุด (หน่วยเป็นวัน)
- Frequency: นับจำนวน
InvoiceNo ทั้งหมดว่าเขาซื้อไปกี่ชิ้น/กี่ครั้ง
- Monetary: ยอดรวมเงินทั้งหมดที่เขาจ่ายให้เรา 💰
Step 3: ปรับสเกลข้อมูล (Standardization) 📏
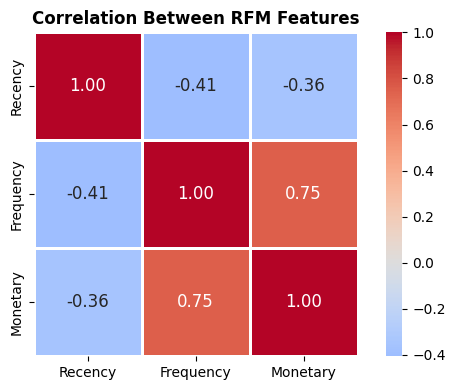
but, waitttt…. ช้าก่อนค่ะ เพราะปัญหาของการเอาข้อมูลเข้า K-Means คือโมเดลจะคำนวณจากระยะห่าง (Distance) ค่ะ ดังนั้นถ้าค่า Monetary เป็นหลักหมื่น แต่ Recency เป็นหลักสิบ โมเดลจะให้ความสำคัญกับเงินมากกว่าทันที เราจึงต้องทำการ Scaling ข้อมูลให้เป็นมาตรฐานเดียวกันก่อน ด้วยสูตรทางคณิตศาสตร์ดังนี้
ซึ่งไม่ต้องนั่งคำนวณเองให้ปวดหัวค่ะ Python จัดให้ตามโค้ดต่อไปนี้ค่ะ
# เลือกเฉพาะคอลัมน์ R, F, M มาใช้งาน
features = rfm[[‘Recency’, ‘Frequency’, ‘Monetary’]]
# ปรับสเกลข้อมูลด้วย StandardScaler
scaler = StandardScaler()
scaled_features = scaler.fit_transform(features)
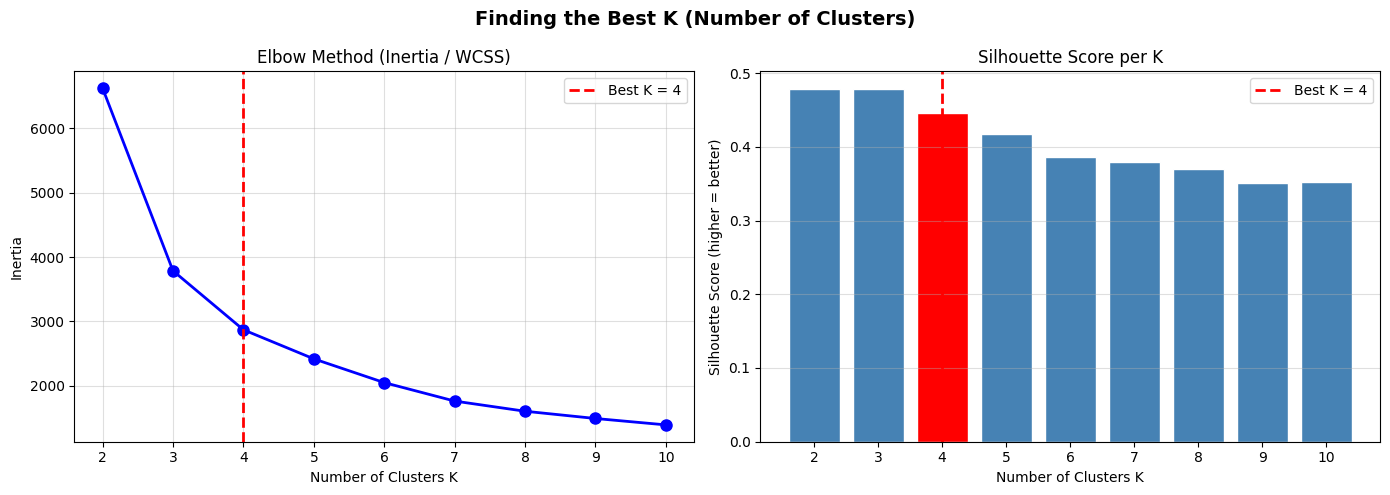
🦾 Step 4: หาจำนวนกลุ่มที่เหมาะสมด้วย Elbow Method
ซึ่งคำถามที่สำคัญมากๆ ในการทำ Customer Segmentation คือแล้วจำนวนกลุ่มลูกค้าที่เหมาะสมที่เราจะแบ่งเป็นกี่กลุ่มดี เพราะสำหรับ K-Means เราต้องระบุจำนวนกลุ่ม (K) ไปก่อนค่ะ
โดยวิธีหา K ที่เหมาะสมที่นิยมสุดคือ Elbow Method โดยเราจะดูค่าความคลาดเคลื่อนภายในกลุ่ม หรือที่เรียกว่า WCSS (Within-Cluster Sum of Squares) ตามสมการต่อไปนี้
wcss = []
K_range = range(1, 11) # ลองแบ่งตั้งแต่ 1 ถึง 10 กลุ่ม
for k in K_range:
kmeans = KMeans(n_clusters=k, random_state=42, n_init=10)
kmeans.fit(scaled_features)
wcss.append(kmeans.inertia_) # ค่า inertia_ คือ WCSS
#Plot กราฟดูจุดข้อศอก
plt.plot(K_range, wcss, marker=’o’)
plt.title(‘Elbow Method For Optimal k’)
plt.xlabel(‘Number of Clusters (k)’)
plt.ylabel(‘WCSS’)
plt.show()
วิธีดูผลลัพธ์: ให้สังเกตกราฟค่ะว่าจุดไหนที่เส้นกราฟเริ่มหักศอกแบบชัดเจน (ความลาดชันลดลงอย่างเห็นได้ชัด) สมมติว่าในกราฟนี้หักศอกที่ 3 หรือ 4 เราก็สามารถเลือกค่านั้นมาใช้ได้เลย ในที่นี้เราเลือก 4 กลุ่มนะคะ ^^
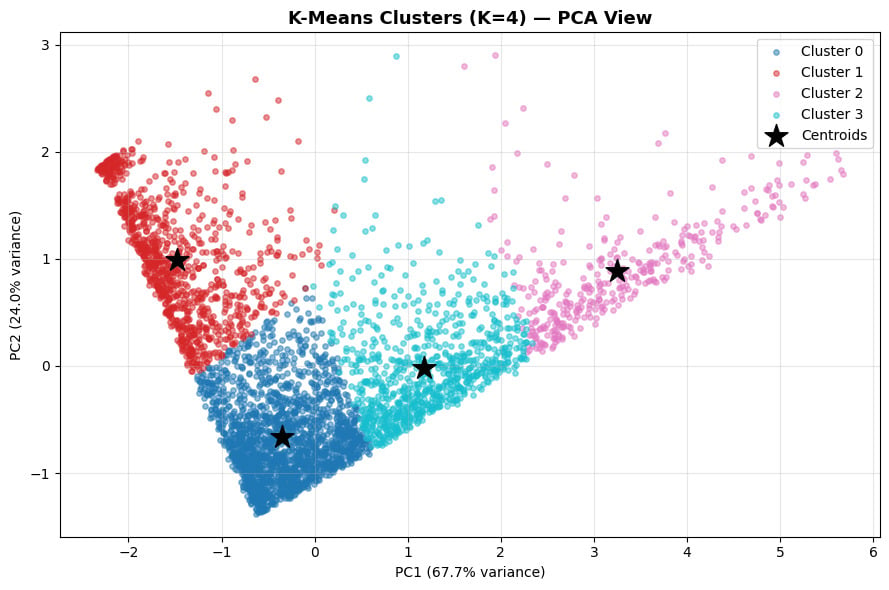
Step 5: ลงมือจัดกลุ่มด้วย K-Means Clustering
เมื่อเราได้จำนวนกลุ่ม K=4 แล้ว เราก็เรียกใช้ K-Means ใน Lib Sklearn ให้ทำหน้าที่จัดกลุ่มลูกค้าให้เราค่ะ
# สร้างโมเดลโดยกำหนดให้ K = 4
kmeans_model = KMeans(n_clusters=4, random_state=42, n_init=10)
# ทำการเทรนและทำนายกลุ่มลูกค้าทันที
rfm[‘Cluster’] = kmeans_model.fit_predict(scaled_features)
print(“จำนวนลูกค้าในแต่ละกลุ่ม:”)
print(rfm[‘Cluster’].value_counts())
โดยคำสั่ง fit_predict() คือการโยนข้อมูลเข้าไปให้โมเดลหาจุดศูนย์กลาง (Centroids) และจัดว่าลูกค้าคนไหนอยู่ใกล้จุดศูนย์กลางของกลุ่มไหนมากที่สุด ก็จะได้ป้ายแปะ (Label) ว่าเป็นกลุ่ม 0, 1, 2, หรือ 3 กลับมาใส่ในคอลัมน์ Cluster ในตารางของเราค่ะ
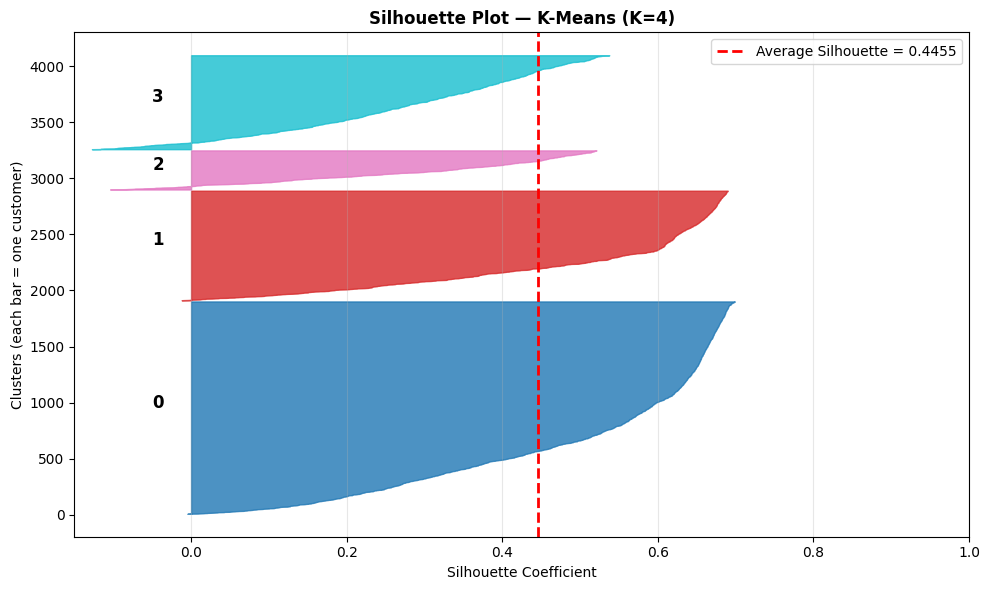
Step 6-9: วัดคุณภาพของโมเดลด้วย Silhouette Score
เมื่อจัดกลุ่มเสร็จแล้ว จะรู้ได้ว่าการแบ่งกลุ่มนั้นเหมาะสมหรือไม่ด้วยค่า Silhouette Score 📊 ซึ่งจะมีค่าตั้งแต่ -1 ถึง 1 ค่ะ(ยิ่งใกล้ 1 แปลว่าจัดกลุ่มได้ดี ลูกค้าแต่ละกลุ่มแยกจากกันชัดเจน
score = silhouette_score(scaled_features, rfm[‘Cluster’])
print(f”Silhouette Score: {score:.2f}”)
ป.ล. ใน Colab ตัวอย่าง โค้ดจะละเอียดกว่าในนี้ และมีการพาทดลองใช้อัลกอริทึมอื่น ได้แก่ DBSCAN ด้วยนะคะ
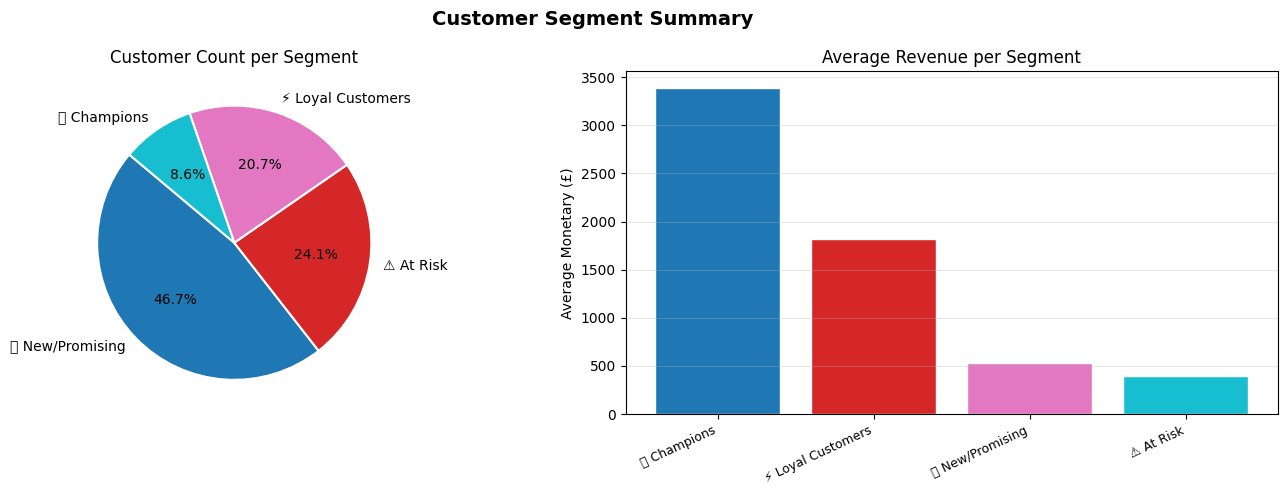
การตีความและวิเคราะห์พฤติกรรม (Interpretation)
ขั้นตอนสุดท้ายคือการเปลี่ยนตัวเลขให้เป็นกลยุทธ์ทางธุรกิจ โดยมีการแบ่งกลุ่มลูกค้าเป็น 4 ประเภทหลัก:
- 🏆 Champions: ซื้อล่าสุด บ่อย และจ่ายหนัก
กลยุทธ์: ให้สิทธิพิเศษ/เข้าถึงสินค้าใหม่ก่อนใคร
- ⚡ Loyal Customers: ซื้อประจำ ยอดจ่ายสม่ำเสมอ
กลยุทธ์: ระบบสะสมแต้ม/โปรโมชัน Upselling
- 🌱 New/Promising: เพิ่งเริ่มซื้อแต่ยังไม่บ่อย
กลยุทธ์: ส่งอีเมลต้อนรับ/ส่วนลดสำหรับการซื้อครั้งที่สอง
- ⚠️ At Risk: เคยซื้อประจำแต่เริ่มหายไป
กลยุทธ์: ส่งแคมเปญ We miss you พร้อมส่วนลดดึงดูด
Last but not Least,,
นิกหวังว่าเนื้อหาในเชิงปฏิบัติของการทำ Customer Segmentation ที่ใช้ K-Means ร่วมกับ RFM นี้จะช่วยให้เราไม่ต้องเดาใจลูกค้าอีกต่อไป แต่ใช้ Data เป็น Guideline แทน และทำให้ทุกคนเห็นว่า Data Science for Marketing ไม่ใช่เรื่องไกลตัว แต่เป็นเครื่องมือชิ้นสำคัญในการทำการตลาดในยุค Marketing 6.0 นี้ค่ะ^^
Ref: ML model(s) หรือ RFM: Customer Segmentation ข้อมูลนี้ใช้โมเดลอะไรดี? (ปณยา สุดตา, 2023)
Raw Data: ชุดข้อมูล Online Retail UCI