เรามาทำความรู้จักทั้งสองวิธีกันสักนิดดีกว่า จะได้คุยกับทีม Tech และ Data เข้าใจมากขึ้น
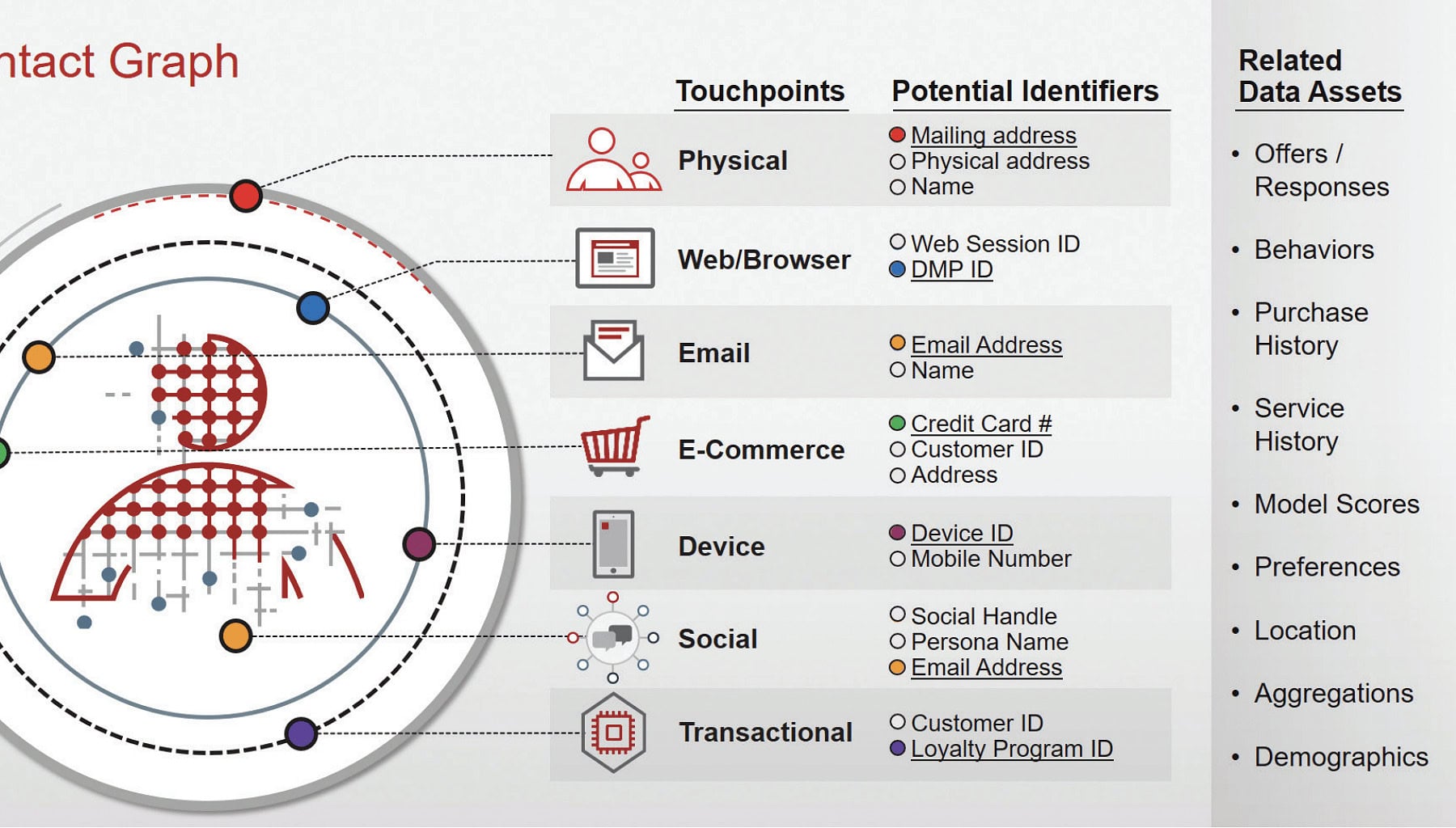
Deterministic ID Matching
สรุปง่ายๆ คือการ Stitching Customer Data แบบ Manual ก็ได้ครับ ก็คือการ Query Data หาทีละส่วนที่สามารถ Identify Customer ID ได้ เช่น อีเมล เบอร์โทร หรือ Username ที่สมัครกับเราไว้
ซึ่งวิธีนี้จะค่อนข้างมีความแม่นยำสูง ผิดพลาดได้ยาก เหมาะมากกับ First-party data ที่เก็บไว้ค่อนข้างพร้อมระดับหนึ่ง
ถ้าใครทำ Power BI เป็นหน่อยก็คิดถึงการทำ Data Relationship ก็ได้ครับ
Probabilistic ID Matching
วิธีการนี้จะแอดวานซ์กว่า เพราะจะใช้ AI หรือ Machine Learning หาจากการใช้หลักสถิติความน่าจะเป็นว่า Custumer ID นี้น่าจะตรงกับ Customer Profile ไหน
อาจจะใช้จาก IP address หรือดูจาก Location base ที่ใกล้กัน หรือดูจาก Device ที่มีการใช้เป็นประจำ ดูจาก Browser ที่ใช้ และก็อาจจะดูจาก OS ประกอบด้วย
ทั้งหมดที่พูดมาไม่ได้ดูแค่ค่าใดค่าหนึ่ง แต่ดูจากทุกค่าเพื่อหาความน่าจะเป็นมากที่สุด จากนั้นระบบก็จะไปทำการ Stitching Customer ID ให้ แต่การทำวิธีนี้จะมีความแม่นยำที่น้อยกว่า Deterministic ID Matching ดังนั้นต้องใช้การตัดสินใจร่วมกันอีกทีหนึ่งว่าควรเชื่อหรือไม่เชื่อที่ AI แนะนำ
อาจต้องมีการดูหลายๆ Attribution ประกอบกัน ซึ่งวิธีนี้จะเหมาะกับบริษัทที่ทำ First-party data ได้ดีแล้ว หรือมี First-party data จำกัด เพราะนี่จะเป็นการใช้ Second-party data หรือ Third-party data เป็นหลักครับ
ซึ่งในการจะทำ Customer Identity Resolution จริงๆ แล้วเลือกวิธีใดวิธีหนึ่งไม่ได้ ควรทำสองแบบไปพร้อมกัน ทำ First-party data ให้ดี จากนั้นก็เชื่อม Third-party data ให้ดีด้วย เพื่อที่ Customer Data เราจะได้มีความ Enrich มากที่สุดครับ
ตรากตรำทำ Identity Resolution ก็เพื่อนำไปสู่การทำ Predictive Model
ทั้งหมดทั้งมวลคือการนำไปสู่การทำ Predictive Model หรือ Predictive Marketing นั่นก็คือการใช้ Data-Driven Marketing นั่นเองครับ
จากนั้นเราก็สร้าง Training data ขึ้นมาว่ากลุ่ม Segments ที่เราต้องการนั้นเป็นอย่างไร จากนั้นระบบ Machine Learning หรือ AI ก็จะไปวิ่งหาคนที่คล้ายกับ Data set ตั้งต้นเราให้ หลักการก็เหมือนกับการทำ Lookalikes ใน Facebook Ads นี่แหละครับ
ซึ่งเริ่มต้น AI จะไปสร้าง Predictive Model มาให้เราก่อนว่า จาก Traning Data ที่เราใส่เข้าไปให้ AI เรียนรู้ แล้วมันก็ไปหา Pattern ว่ากลุ่ม Segment ที่เราอยากได้นั้นมี Pattern ของ Attributes อย่างไรบ้าง
เมื่อเราได้ผลลัพธ์มาที่เหลือก็ขึ้นอยู่กับวิจารณญาณของเรา ว่าเราจะเชื่อที่ AI แนะนำมาทั้งหมดเลยไหม หรือจะเพิ่ม Attribution ไหน หรือจะลดตัวแปรใดที่ดูแล้วไม่ Make sense ก็ตาม
จะเห็นว่าทั้งหมดนี้หลักการไม่ยาก มันคือการ Training data ตั้งต้นเพื่อให้ AI ไปเรียนรู้หา Pattern เพื่อหาคนที่คล้ายๆ กับคนกลุ่ม Segment ที่เราอยากได้ออกมา แล้วเราก็ตรวจงาน AI ดูว่ามันน่าจะใช่มากน้อยแค่ไหน
แต่ทั้งหมดนี้จะเกิดขึ้นไม่ได้เลยถ้าเราไม่มี Traning data ที่ดีแต่แรก ถ้าเราไม่ทำ Customer Identity Resolution เป็น Golden Record ไว้ให้ดี เราก็จะไม่มีทางเห็นภาพ Customer Profile ที่เราอยากได้เป็นสารตั้งต้นส่งต่อให้ AI เรียนรู้ครับ
ดังนั้นจะ Lookalikes แม่นหรือไม่แม่นก็ขึ้นอยู่กับ Data set สารตั้งต้นนี่แหละครับ
เพราะในการตลาดยุคดาต้า เราพูดคำว่า Garbage in, Garbage out ได้เต็มปา ก ถ้าเราเอา Training data ตั้งต้นไม่ดีใส่เข้าไป ผลลัพธ์จากการ Lookalikes เราก็จะแย่จนแทบไม่ต่างจาก Mass Marketing ยุคเก่าเลย
รู้แบบนี้แล้วรีบประกอบเชื่อม Customer ID ที่กระจัดกระจายให้ได้นะครับ รีบรู้ให้ได้ว่าคนที่กำลังกดอ่านคอนเทนต์เราอยู่เป็นใคร เขาเป็นลูกค้าเราอยู่แล้วหรือเป็นคนหน้าใหม่ที่เพิ่งเข้ามา หรือเขาเป็นคนที่สนใจเราอยู่พักใหญ่แต่ยังไม่ตัดสินใจซื้อสักที เห็นไหมครับถ้าเรารู้แค่นี้ วิธีทำการตลาดเราก็จะง่ายเหมือนจับวางแล้ว
FacebookFacebookXXLINELineในช่วงไม่กี่ปีที่ผ่านมา คำว่า AI อาจเคยถูกเข้าใจว่าเป็นเพียงเครื่องมือช่วยตอบคำถาม ช่วยเขียนข้อความ หรือช่วยสรุปข้อมูลให้เร็วขึ้น แต่จากอัปเดตล่าสุดของ Google ในช่วงเดือนเมษายน 2026 ภาพของ AI กำลังเปลี่ยนไปอย่างชัดเจน เพราะ Google ไม่ได้พูดถึง AI ในฐานะ Chatbot อีกต่อไป แต่กำลังวาง AI ให้กลายเป็นโครงสร้างพื้นฐานของการทำงาน การเรียนรู้ การสร้างสรรค์ และการใช้ชีวิตในระดับที่ลึกกว่าเดิม บทความนี้จะพามาดู AI Update Google ทำอะไรกับ AI ในปี 2026 สรุปอัปเดตใหญ่ที่ต้องรู้ AI สำหรับองค์กร เมื่อ Google กำลังผลักดันโลกเข้าสู่ยุค AI Agent ภาพใหญ่ที่สุดของ AI Update ครั้งนี้คือการที่ Google กำลังผลักดันโลกเข้าสู่สิ่งที่เรียกว่า Agentic Era หรือยุคของ AI Agent ซึ่งหมายถึง AI […]