สวัสดีค่ะเพื่อนๆ สาย Tech และนักการตลาดทุกท่าน เมื่อ 2-3 ปีที่แล้ว เราได้ตื่นเต้นกับความสามารถในการตอบคำถามของ ChatGPT, Bard (Gemini), Deepseek ที่เข้ามาใหม่กันใช่มั้ยคะ แต่ตัดภาพมาที่ปัจจุบันเมื่อโลกของ Generative AI และ Large Language Models (LLMs) ได้ก้าวผ่านจุดที่ GenAI เป็นแค่แชทบทผู้ช่วยเลขาส่วนตัวไปไกลมากกก แต่ได้มีการถูกสร้างและใช้งานในรูปแบบ Autonomous Agents ที่สามารถคิดวิเคราะห์เชิงลึก และลงมือทำงานจริงได้อย่างแม่นยำ อย่างเช่น Qwen ที่นิกกำลังจะเล่าให้อ่านกันค่ะ^^
บทความนี้เราจะไปทำความรู้จักกับ Qwen จากค่าย Alibaba ที่เป็น Open-weight Model หรือก็คือ AI เจ้าของเปิดค่าพารามิเตอร์ หรือในที่นี้ก็คือ weights ของตัวโมเดลให้เราดาวน์โหลดไปใช้งานได้ โดยไม่จำเป็นต้องเรียกผ่าน cloud ซึ่งโมเดลลักษณะนี้เริ่มมีการถูกใช้งานในวงกว้างมากขึ้นเรื่อยๆ ทั้งในส่วนของ Developer เองและในส่วนงานด้าน Digital/ Autonomous Marketing ค่ะ โดยนิกจะพาทุกคนไปเจาะลึกโมเดลนี้กันแบบค่อนข้างละเอียด ซึ่งอาจจะมีการแบ่งบทความเป็นหลายพาร์ท โดยเริ่มต้นที่บทความนี้ =>> พร้อมแล้วลุยกันเลยค่ะ (/ω\ )
#0 Qwen ยุคแรกแบบ Decoder-only
Qwen จาก Alibaba ในยุคแรกเป็นโมเดลที่ใช้ Nueronnetwork แบบ Decoder-only คล้ายๆ กับ Llama ที่ใช้ RMS-Norm และฟังก์ชัน SwiGLU แต่ความไม่ธรรมดาคือโมเดลนี้มีการปรับแต่งโครงสร้างภายในแบบเฉพาะตัวเพื่อให้โมเดลทำงานได้ดีขึ้นดังนี้ค่ะ
Untied Embedding Matrix: โมเดลทั่วไปจะเน้นประหยัดพื้นที่ VRAM โดยการผูกน้ำหนัก (Weight Sharing) ระหว่างขาเข้า และขาออกเข้าด้วยกัน แต่ Qwen-v1 เลือกที่จะแยกทั้งสองอย่างนี้ออกจากกัน (Untied) เป็น Matrix ขนาด vocab_size×d_model จำนวน 2 ชุดอิสระ ซึ่งถึงแม้จะเปลืองหน่วยความจำขึ้น แต่ช่วยให้สัญญานขาเข้า และขาออกสกัด Feature ได้ตรงมากยิ่งขึ้นค่ะSelective Bias Elimination: หรือการเลือกถอดตัวแปร Bias ออกเกือบทุก Layers ยกเว้นในชั้น QKV (Query, Key, Value) ของ Attention Layer เท่านั้น เพื่อไม่ให้โมเดล Overfitting ซึ่งการคง Bias ไว้ที่จุดนี้จะช่วยให้โมเดลขยายขอบเขตบริบทได้ยาวขึ้น (Length Extrapolation) ค่ะHierarchical Window Self-Attention: มีการจัดเลเยอร์แบบลำดับขั้น เลเยอร์ล่างๆ จะใช้ Window Attention สั้นหน่อย ส่วนเลเยอร์ก่อนหน้าจะขยายให้ยาวขึ้น ซึ่งเมื่อทำงานร่วมกับอัลกอริทึม RoPE และ YaRN จะทำให้อ่านบริบทได้ยาวถึง 8,192 Tokens จากเดิมที่เทรนมาแค่ 2,048 Tokens ค่ะ ╰(°▽° )╯
และสิ่งที่เป็นหัวใจสำคัญในการทำให้โมเดลนี้พูดจารู้เรื่องคือเทคนิคเรื่องการจัดตำแหน่ง (Alignment) ด้วยกระบวนการ RLHF (Reinforcement Learning from Human Feedback) ผ่าน Optimizer PPO (เดี๋ยวสมการ นิกจะมาลงรายละเอียดในบทความต่อไปนะคะ^^)
#1 Qwen2.5 โมเดลที่แก้ Bug และคำนวณได้จริง
แต่พอมาถึงยุค Qwen2.5 ยุทธศาสตร์ของ Alibaba ได้เปลี่ยนไปอย่างชัดเจนค่ะ ซึ่งทีมพัฒนามีการใช้เทคนิค Grouped-Query Attention (GQA) เพื่อบีบ KV Cache ให้เล็กลง และอัดฉีดข้อมูล Pre-training จำนวนมากถึง 18 ล้านล้านโทเคน (18T Tokens) ซึ่งสิ่งนี้ส่งผลให้เกิดการแบ่งโมเดลออกเป็นขนาดต่างๆ ตั้งแต่ 0.5B, 1.5B, 3B, 7B, 14B, 32B ไปจนถึงตัวใหญ่อย่าง 72B เพื่อให้เหมาะกับงบ Status GPU ของ User แต่ละรายค่ะ
ป.ล. สำหรับเพื่อนๆ ท่านไหนที่อ่านแล้วงงๆ สามารถเข้าไปอ่านเนื้อหาในบทความก่อนหน้าเรื่อง LLMs, Pretraining Model ได้เลยนะคะ ซึ่งนิกจะแปะลิงก์ไว้ Refernces ค่ะ^^
โดยสำหรับจุดเด่นของ Qwen2.5 คือการที่โมเดลเริ่มมีการแตกไลน์เป็นผู้เชี่ยวชาญเฉพาะทาง หรือ Domain Specialization Forks ออกมา ได้แก่
Qwen2.5-Coder: เหมาะกับการเป็นผู้ช่วยเขียนโค้ด เนื่องจากมีการใส่ trianing data เป็นข้อมูล sourcecode เพิ่มไปอีก 5.5T Tokens เพื่อให้โมเดลนี้สามารถช่วยเขียนโค้ดและแก้บั๊กได้Qwen2.5-Math: เป็นโมเดลสายคำนวณขั้นสูง ซึ่งมีกระบวนการคิดแบบ Chain-of-Thought (CoT) และ Program-of-Thought (PoT) ร่วมกับ TIR (Tool-Integrated Reasoning) ทำให้เวลาเจอสมการยากๆ ตัวโมเดลจะไม่นั่งเดาตัวเลขมั่วๆ (แบบที่เราชอบเจอกัน 555+) แต่จะเขียนโค้ดสคริปต์ส่งไปให้โปรแกรมภายนอกคำนวณ แล้วค่อยดึงผลลัพธ์ที่ถูกต้อง กลับมาตอบเราแทนค่ะ =>> สรุปคือมีการคำนวนเกิดขึ้นจริง 😎
#3 Qwen3 และ 3.6-Plus
สำหรับ Qwen3 เป็นโมเดลที่รวมโหมดแชตไว และโหมดคิดลึกเข้าไว้ในโมเดลเดียวกัน ผ่านโครงสร้างแบบ Mixture-of-Experts (MoE) โดยเฉพาะ Qwen3-235B-A22B ที่มีพารามิเตอร์รวมในระบบมากระดับ 235 พันล้านตัว แต่ด้วยความเป็น MoE ตัวโมเดลจะเลือกเปิดใช้ NN parameters ที่จำเป็นเพียง 22 พันล้านพารามิเตอร์ต่อหนึ่งโทเคนก่อนเท่านั้นค่ะ เพื่อประหยัด Tokens ให้เราแต่ยังคงประมวลผลและตอบกลับได้เร็วเหมือนเดิม
ซึ่งใช้เทคนิค qk layernorm ทำ Normalization ที่เวกเตอร์ Query และ Key ก่อนจับคูณกันเพื่อป้องกัน Variance ไม่ให้สูงเกินไป และใช้ Global-batch Load Balancing Loss คอยคุมไม่ให้ Gateway ส่งงานไปรุมที่ Expert ตัวใดตัวหนึ่งจนเกิดคอขวด รวมถึงมีระบบ Unified Thinking Framework รายละเอียดดังนี้ค่ะ
Thinking Mode: โมเดลจะบังคับตัวเองให้เข้าสู่กระบวนการคิดวิเคราะห์เชิงลึกเมื่อเจอ Prompt ยากๆ โดยซ่อนขั้นตอนการพิจารณาเหตุผลไว้ในบล็อก <think> ในลักษณะ Test-Time Compute ScalingThinking Budget Mechanism: เราสามารถตั้งค่าจำนวน Tokens ที่จะใช้ได้ค่ะ ว่าต้องการให้ AI คิดยาว in deep ขนาดไหน หรือจะจำกัดให้คิดสั้นๆ เพื่อเน้นความเร็วในแบบ Low Latency ได้
นอกจากนี้ Post-training มีการใช้อัลกอริทึม GRPO (Group Relative Policy Optimization) ที่สามารถตัดโมเดลตัววิจารณ์ (Critic Model) ทิ้งไป แล้วใช้การสุ่มคำตอบออกมาเป็นกลุ่มเพื่อหาค่าเฉลี่ย และเปรียบเทียบรางวัลสัมพัทธ์กันเองในกลุ่มแทน ซึ่งการตัด Critic ออกไปช่วยประหยัด VRAM ได้เยอะมากๆ ค่ะ ทำให้เราสามารถทำ Knowledge Distillation ถ่ายทอดกระบวนการคิดจากโมเดลใหญ่ ลงมาสู่โมเดลขนาดเล็กอย่าง 4B หรือ 8B ให้มีความฉลาดขึ้นได้ง่ายๆ 😏😁
และในส่วนของ Qwen 3.6-Plus ถูกออกแบบภายแนวคิดที่ว่า “Designed to Execute, Not Just Explain” เพื่อให้สามารถสร้างระบบ Autonomous Agent ได้ โดยการทำ Agentic Loop คือการคิด –>ใช้เครื่องมือ –> รับผลลัพธ์ –> ทำต่อ โดยมีการคำนวณค่ำความล้มเหลวสะสม (Compound Error Rate) ให้เน้นความน่าเชื่อถือระดับสูง (Per-step Reliability)
และมีเทคนิคการคิดแผนสำรอง (Fallback) และกู้คืนความผิดพลาดเมื่อ Tool ส่งค่า Error กลับมา (Failure Recovery) โดยรองรับระบบ Strict Structured Outputs ที่มีการทำงานร่วมกับ Pydantic เพื่อบังคับให้ Output อยู่นในรูปแบบ JSON ซึ่งเป็นข้อมูลประเภท Type-safe ที่ถูกต้อง 100% ไม่มีการหลอนหรือ Hallucinate ส่งวงเล็บตกหล่นให้ระบบ Backend พังแน่นอนค่ะ นอกจากนี้สิ่งที่นิกคิดว่ามีประโยชน์มากๆ คือการมี History Compression ที่คอยบีบอัดประวัติการเรียก Tool ก่อนหน้า เพื่อประหยัดพื้นที่หน้าต่างบริบทหรือ Context Window Token Budget ค่ะ^^
#4 การใช้งาน qwen.ai
อ่านมาถึงตรงนี้นิกเชื่อว่า ทุกท่านน่าจะเห็นตรงกันค่ะว่าสำหรับในยุคนี้ Marketing Automation แบบ If-Else รูปแบบเดิมตาม Costomer Journey ไม่ทันแล้ว ดังนั้นการมาของ Qwen 3.6-Plus รวมถึง AI-Agents ตัวอื่นๆ อย่าง n8n, make.com จะเปลี่ยนเราสู่ยุคการตลาดแบบ Autonomous Agent สายปฏิบัติการจริง ซึ่งในบทความนี้สำหรับ Qwen 3.6-Plus มี 3 จุดเด่นหลักดังนี้ค่ะ
Autonomous Agent: Qwen 3.6-Plus ช่วยให้เราสร้างเอเจ้นต์นักการตลาดส่วนตัว ที่เข้าใจบริบทลึกซึ้ง และคิดขั้นตอนการทำงานต่อยอดเองได้แบบอัตโนมัติ จากยุคก่อนที่เราทำ Marketing Automation โดยการตั้งเงื่อนไขแบบ If-Else เช่น ถ้าลูกค้ากดลิงก์นี้ ให้ส่งอีเมลฉบับนั้น แต่ปัจจุบันคือไม่ต้องแล้วค่ะWorkflow ที่ความผิดพลาดต่ำ: ด้วยโมเดลและเทคนิคที่ทำให้ค่า Compound Error Rate ให้เข้าใกล้ 1.0 และรองรับ Strict Structured Outputs ทำให้เราสามารถรันลูปงานยาวๆ เช่น การตรวจพฤติกรรมบนเว็บ คำนวณค่า CLV –> คัดกรองกลุ่ม Churn Risk–> เขียนข้อความ Hyper-personalized–> ส่งคำสั่งยิงแคมเปญหลังบ้าน ได้อย่างแม่นยำ และ ( Alibaba เคลมว่า)ไม่มีอาการหลอนพ่นโค้ดพัง หรือส่งคูปองส่วนลดผิดพลาดให้แบรนด์เสียหายค่ะมี Firewall, Data Privacy Compliance: เนื่องจาก Qwen เป็นโมเดลแบบ Open-weight ที่เรา download ค่าพารามิเตอร์ต่างๆ มาใช้แบบ Local ได้ ทำให้ข้อมูลพฤติกรรมการซื้อ ข้อมูลยอดขาย หรือข้อมูลส่วนบุคคลของลูกค้า จะไม่รั่วไหลออกไปยัง API ภายนอกสำหรับข้อมูลที่มีความเปราะบางค่ะ^^
และส่วนท้ายสุด นิกจะชวนเพื่อนๆ นักการตลาด/ผู้สนใจทุกท่านทดลองใช้งาน Qwen AI โดยเข้าไปที่ https://qwen.ai/home แล้ว Login หรือ Signin หลังจากนั้นสามารถ Copy ตัว Prompt ด้านล่างนี้ลงไปวางในช่องแชทได้เลยค่ะ^^
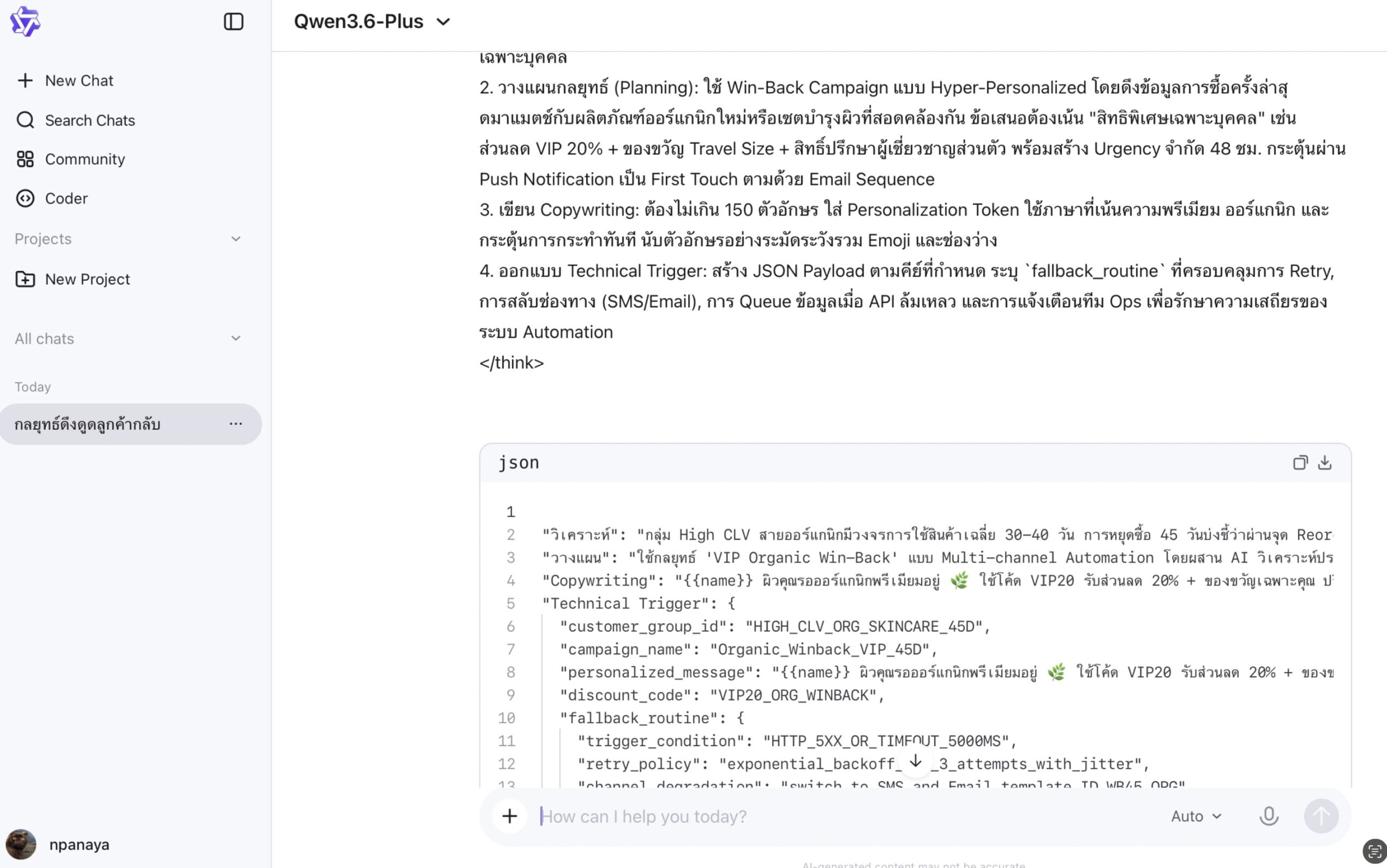
Prompt:
จงคิดแบบ Multi-step และตอบเป็นโครงสร้าง JSON ตามสเตปต่อไปนี้:
[วิเคราะห์] สาเหตุที่หยุดซื้อของกลุ่มนี้[วางแผน] กลยุทธ์ Retention Campaign และข้อเสนอที่เหมาะสมเพื่อดึงกลับมา[Copywriting] ข้อความ Push Notification (ไม่เกิน 150 ตัวอักษร) แบบ Hyper-personalized[Technical Trigger] ออกแบบ JSON Payload ส่งให้ระบบหลังบ้าน โดยระบุคีย์: customer_group_id, campaign_name, personalized_message, discount_code และ fallback_routine (แผนสำรองหาก API พัง)
หมายเหตุ: แสดงกระบวนการคิดในบล็อก <think> ก่อนส่งผลลัพธ์ JSON สุดท้าย
Last but not Least,,
สรุปว่า….ในบทความนี้เพื่อนๆ ชาวการตลาดวันละตอนจะได้ทำความรู้จักในเบื้องต้นกับ Qwen ซึ่งมีกระบวนการข้างในยิบย่อย ยุบยับ เพื่อที่จะสามารถสร้างความเข้าใจและทราบ Keywords ตลอดจนหลักการทำงานของโมเดลรูปแบบต่างๆ โดยเฉพาะ Autonomous Agent ซึ่งรายละเอียดต่างๆ เพิ่มเติมของแต่ละโมเดล และตัวอย่างการใช้งาน อื่นๆ สามารถติดตามได้ในบทความ part ต่อไปนะคะ ╰(°▽° )╯
References:
[1] ทำความรู้จัก LLMs: แบบจำลองภาษาขนาดใหญ่ เทคโนโลยีเบื้องหลัง AI ChatGPT . (2023) ปณยา สุดตา. การตลาดวันละตอน.QWEN TECHNICAL REPORT . (2023). Qwen Team, Alibaba Group.GRPO: คณิตศาสตร์และโมเดลเบื้องหลัง DeepSeek . (2025) ปณยา สุดตา. การตลาดวันละตอนทำไม Customer Lifetime Value (CLV) ถึงสำคัญ? . (2021) Plearn Wisetwongchai . การตลาดวันละตอน