ถ้าคุณเคยรู้สึกว่า GPT รุ่นก่อนก็เก่งแล้วนะ แต่การอัปเดต GPT-5.2 ของ OpenAI ทำให้เห็นภาพชัดขึ้นว่า รอบนี้ไม่ได้แค่เก่งขึ้นอย่างเดียว แต่มันทำงานจบเป็นชิ้น ได้ดีขึ้นในหลาย ๆ ด้าน โดยเฉพาะงานที่คนทำงานจริงเจอทุกวัน สเปรดชีต พรีเซนเทชัน โค้ด งานอ่านเอกสารยาว งานดูภาพ/แดชบอร์ด และงานที่ต้องใช้เครื่องมือหลายขั้นตอน บทความนี้จะพามาดูว่า อัปเดต GPT-5.2 เทียบรุ่นก่อน มีอะไรใหม่ และดีขึ้นตรงไหนบ้างครับ
อัปเดต GPT-5.2 เทียบรุ่นก่อน มีอะไรใหม่ และดีขึ้นตรงไหนบ้าง
ชื่อการทดสอบ (Benchmark) GPT‑5.2 Thinking GPT‑5.1 Thinking GDPval (wins or ties) Knowledge work tasks 70.9% 38.8% (GPT‑5) SWE-Bench Pro (public) Software engineering 55.6% 50.8% SWE-bench Verified Software engineering 80.0% 76.3% GPQA Diamond (no tools) Science questions 92.4% 88.1% CharXiv Reasoning (w/ Python) Scientific figure questions 88.7% 80.3% AIME 2025 (no tools) Competition math 100.0% 94.0% FrontierMath (Tier 1–3) Advanced mathematics 40.3% 31.0% FrontierMath (Tier 4) Advanced mathematics 14.6% 12.5% ARC-AGI-1 (Verified) Abstract reasoning 86.2% 72.8% ARC-AGI-2 (Verified) Abstract reasoning 52.9% 17.6%
ตารางนี้คือ ตารางเปรียบเทียบประสิทธิภาพของ GPT-5.2 Thinking กับรุ่นก่อนหน้า (หลัก ๆ คือ GPT-5.1 Thinking และบางแถวเทียบกับ GPT-5) เพื่อให้เราเห็นว่า รุ่นใหม่ดีขึ้นแค่ไหน ในงานประเภทใดบ้าง ไม่ใช่คำอธิบายเชิงความรู้สึก แต่เป็นคะแนนจาก benchmark มาตรฐานที่ใช้ในวงการ AI ครับ
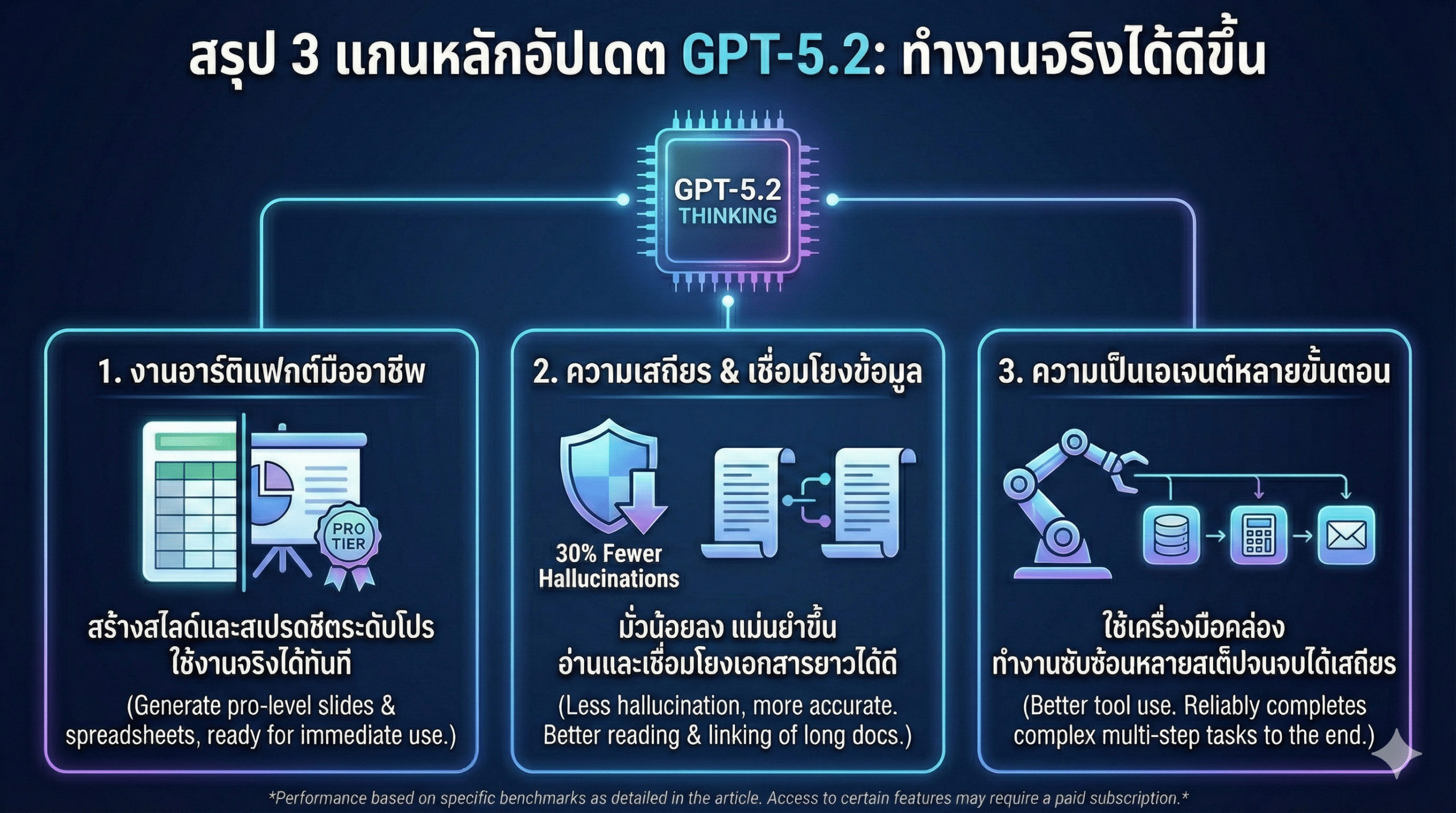
1) GDPval (wins or ties) Knowledge work tasks คือตการวัดความสามารถในการผลิตงานความรู้ที่ขอบเขตชัดครอบคลุม 44 อาชีพ เช่น ทำสไลด์ขาย ทำสเปรดชีตบัญชี จัดตารางเวร วาดไดอะแกรมการผลิต หรือทำวิดีโอสั้น ซึ่ง GPT-5.2 Thinking 70.9% รุ่นก่อน 38.8%
พูดง่าย ๆ คือ GPT-5.2 ชนะหรืออย่างน้อยก็ทำได้พอ ๆ กับผู้เชี่ยวชาญมนุษย์ เกือบ 71% ของงานทั้งหมด ขณะที่รุ่นก่อน ทำได้แค่ราว 4 งานจาก 10 นี่คือเหตุผลที่ OpenAI บอกว่า GPT-5.2 เป็นรุ่นแรกที่แตะระดับผู้เชี่ยวชาญในงานความรู้ด้านอาชีพ
อีกจุดที่หลายคนจะชอบคือ ใน ChatGPT รุ่น Thinking/Pro มีเครื่องมือใหม่ที่รุ่น Thinking เดิมไม่มี และ OpenAI บอกตรง ๆ ด้วยว่า ถ้าจะใช้ความสามารถด้านสเปรดชีต/พรีเซนเทชันแบบใหม่ ต้องอยู่ใน Plus/Pro/Business/Enterprise และเลือก GPT-5.2 Thinking หรือ Pro และงานซับซ้อนอาจใช้เวลาหลายนาทีในการ generate ครับ
2) งานเขียนโค้ด (Software Engineering) มี SWE-Bench Pro และ SWE-Bench Verified สองอันนี้คือโจทย์เขียนโค้ดระดับโลกจริง ไม่ใช่โค้ดตัวอย่างสวย ๆ ผลที่ได้คือ SWE-Bench Pro โดย GPT 5.2 ได้ 55.6% ส่วน GPT 5.1ได้ 50.8% และ SWE-Bench Verified โดย GPT 5.2 ได้ 80.0% และ GPT 5.1 ได้ 76.3%
หมายความว่ารุ่นใหม่สามารถ แก้บั๊ก / รีแฟกเตอร์ / ต่อฟีเจอร์จริงได้แม่นขึ้น ความต่างดูเหมือนไม่เยอะเป็นตัวเลข แต่ในโลกซอฟต์แวร์ เพิ่ม 4–5% คือคุณภาพที่ต่างชัดมาก ครับ โมเดลมีแนวโน้มดีขึ้นในงานที่นักพัฒนาต้องทำจริง เช่น ดีบักโค้ดโปรดักชัน ทำฟีเจอร์ รีแฟกเตอร์โค้ดเบสใหญ่ ๆ และส่งแพตช์แบบ end-to-end โดยต้องพึ่งคนมานั่งแก้มือให้น้อยลง
ทาง OpenAI ยังย้ำด้วยว่า GPT-5.2 Thinking แข็งขึ้นในงาน front-end และ UI ที่ซับซ้อนหรือแปลกใหม่ โดยเฉพาะงานที่มีองค์ประกอบ 3D ซึ่งเป็นกลุ่มงานที่โมเดลหลายรุ่นก่อนหน้ามักรู้สึกติด ๆ ขัด ๆ เวลาต้องคุมประสบการณ์ผู้ใช้พร้อมกับความถูกต้องทางเทคนิคครับ
3) วิทยาศาสตร์ & การอ่านกราฟ โดย GPQA Diamond (no tools) – Science questions GPT 5.2 ได้ 92.4% ส่วน GPT 5.1 ได้ 88.1% และ CharXiv Reasoning (w/ Python) – Scientific figures GPT 5.2 ได้ 88.7% ส่วน GPT 5.1 80.3%
หมายความว่า GPT-5.2 เข้าใจคำถามวิทยาศาสตร์ระดับบัณฑิตศึกษาได้ดีกว่า และอ่านกราฟ/ภาพจาก paper วิจัยแล้วตีความถูกมากขึ้น เหมาะมากกับงานรีเสิร์ช, วิเคราะห์ข้อมูล, เขียนบทความเชิงลึก, สาย Data / Science ครับ
โดย OpenAI บอกว่า GPT-5.2 Thinking หลอนน้อยกว่า GPT-5.1 Thinking โดยจากชุดคำถามแบบไม่ระบุตัวตนใน ChatGPT คำตอบที่มีข้อผิดพลาดน้อยลง 30% และในกราฟคำตอบที่มีอย่างน้อยหนึ่งข้อผิดพลาด อยู่ที่ 6.2% สำหรับ GPT-5.2 Thinking เทียบกับ 8.8% ของ GPT-5.1 Thinking (ภายใต้เงื่อนไข reasoning effort สูงสุดและเปิดเครื่องมือค้นหา)
แปลว่าอะไร? แปลว่าในงานที่เราใช้ AI เป็นแรงเสริมทุกวัน สรุปข้อมูล ทำรีเสิร์ช ทำเด็ค ทำข้อเสนอ ความเสี่ยงของหลุดมั่วแบบเงียบ ๆ ลดลง และทำให้โมเดลไว้ใจได้มากขึ้นในเชิงงานประจำวัน แต่ทั้งนี้ทั้งนั้นการตรวจซ้ำก็เป็นเรื่องสำคัญอยู่ดีครับ
4) คณิตศาสตร์ขั้นสูง โดย AIME 2025 (no tools) GPT 5.2 ได้ 100% ส่วน GPT 5.1 ได้ 94% และ FrontierMath (Tier 1–3 / Tier 4) GPT 5.2 ได้ 40.3% / 14.6% ส่วน GPT 5.1 ได้ 31.0% / 12.5%
ตรงนี้วัดการคิดเชิงนามธรรม + หลายขั้นตอน ไม่ใช่คิดเลขธรรมดา ความหมายคือ GPT-5.2 เก่งขึ้นในโจทย์ยากที่ต้องคิดต่อเนื่องยาว ๆ ซึ่งเป็นฐานสำคัญของการใช้งานให้ AI ทำงานเป็น agent ไม่หลุดกลางทางครับ
5) การคิดเชิงนามธรรม (Abstract / AGI-style reasoning) มี ARC-AGI-1 GPT 5.2 ได้ 86.2% ส่วน GPT 5.1 ได้ 72.8% และ ARC-AGI-2 GPT 5.2 ได้ 52.9% ส่วน GPT 5.1 ได้ 17.6%
อันนี้สำคัญมากเพราะ ARC-AGI คือโจทย์ที่ ไม่เคยเห็นมาก่อน ไม่พึ่งความจำ วัดการคิดล้วน ๆ ดังนั้นการกระโดดจาก 17.6% ไปเป็น 52.9% หมายถึง GPT-5.2 คิดเป็นระบบได้ดีขึ้นแบบก้าวกระโดด ไม่ใช่แค่ฉลาดขึ้นนิดเดียวครับ
อ่านยาวและเชื่อมข้ามไฟล์ดีขึ้น Long-context ที่เป็นประโยชน์จริง
และถ้าคุณทำงานที่ต้องอ่านเอกสารยาว ๆ หรือมีหลายไฟล์ประกอบ เช่น รายงาน สัญญา รีเสิร์ช ทรานสคริปต์ หรือโปรเจกต์ที่ต้องเชื่อมข้อมูลไปมา จุดนี้คืออัปเกรดที่มีมูลค่ามาก
โดย OpenAI บอกว่า GPT-5.2 Thinking ทำได้ดีขึ้นบน OpenAI MRCRv2 และเป็นโมเดลแรกที่เห็นว่าใกล้ 100% บนเวอร์ชัน 4-needle ของ MRCR (ที่ความยาวบริบทสูงสุด 256k tokens) ซึ่งสะท้อนความสามารถในการจับความสัมพันธ์ของข้อมูลที่กระจายอยู่ในเอกสารยาวได้แน่นขึ้น
และสำหรับงานที่ยาวกว่าหน้าต่างบริบทสูงสุด OpenAI ระบุว่า GPT-5.2 Thinking รองรับ Responses /compact endpoint ที่ช่วยขยาย effective context window เพื่อรองรับเวิร์กโฟลว์ที่ใช้เครื่องมือเยอะและรันนาน ซึ่งปกติจะติดเพดานเรื่องความยาวบริบทครับ
มองภาพ/แดชบอร์ด/หน้าจอเก่งขึ้น ใช้งานจริงกับงานสายธุรกิจมากขึ้น
ทาง OpenAI ระบุว่า GPT-5.2 Thinking ลด error rate ลงประมาณครึ่งหนึ่ง ในงาน chart reasoning และ software interface understanding และยกตัวเลขเทียบให้ดู เช่น ScreenSpot-Pro ความแม่นยำ 86.3% เทียบกับ 64.2% ของ GPT-5.1 Thinking (ภายใต้เงื่อนไขเปิด Python tool และ reasoning effort สูงสุด)
ถ้าคุณทำงานกับแดชบอร์ดโฆษณา แผนภูมิยอดขาย ภาพหน้าจอระบบงาน หรือไดอะแกรมเทคนิค ความสามารถนี้แปลเป็นการอ่านรูปแล้วสรุป/ชี้จุดผิด/อธิบายสิ่งที่เห็นได้แม่นขึ้น ซึ่งทำให้งานวิเคราะห์ไวขึ้นแบบสัมผัสได้ครับ
ใช้เครื่องมือและทำงานหลายขั้นตอนแน่นขึ้น เอเจนต์พังน้อยลง
ฝั่ง tool calling GPT-5.2 Thinking ทำ 98.7% บน Tau2-bench Telecom เทียบกับ 95.6% ของ GPT-5.1 Thinking และใน Tau2-bench Retail ก็สูงขึ้นเช่นกัน (82.0% เทียบกับ 77.9%) ประเด็นนี้สำคัญมากสำหรับคนที่ใช้ AI ทำเวิร์กโฟลว์หลายสเต็ป เช่น ดึงข้อมูลจากหลายระบบ วิเคราะห์ แล้วสรุปเป็นผลลัพธ์สุดท้าย เพราะสิ่งที่ทำให้เอเจนต์ใช้จริงไม่ได้ ส่วนใหญ่ไม่ใช่ความฉลาด แต่คือ พังระหว่างทาง และ GPT-5.2 ถูกออกแบบให้จบงาน end-to-end ได้เสถียรกว่า
ทาง OpenAI ยังระบุว่าใน use case ที่ต้องการความหน่วงต่ำ GPT-5.2 ทำได้ดีขึ้นมากเมื่อใช้ reasoning.effort=’none’ โดยยัง outperform รุ่นก่อนหน้าอย่างชัดเจน ซึ่งแปลว่า แม้เราจะลดการคิดหนักเพื่อให้เร็วขึ้น โมเดลก็ยังคุมคุณภาพได้ดีกว่าเดิมครับ
ใช้ใน ChatGPT และ API ต่างกันยังไง: รุ่น/ชื่อ/ราคา
ใน ChatGPT OpenAI ระบุว่า GPT-5.2 Instant, Thinking และ Pro เริ่มทยอยปล่อย (เริ่มจากแผนจ่ายเงิน) และ GPT-5.1 จะยังอยู่ให้ผู้ใช้แบบจ่ายเงินใน legacy models อีกสามเดือนก่อนจะทยอยยุติใน ChatGPT
ใน API ชื่อโมเดลถูกระบุชัดขึ้น เช่น ChatGPT-5.2 Instant คือ gpt-5.2-chat-latest ส่วน ChatGPT-5.2 Thinking คือ gpt-5.2 และ ChatGPT-5.2 Pro คือ gpt-5.2-pro และเพิ่ม reasoning effort ระดับ xhigh ให้กับทั้ง Pro และ Thinking สำหรับงานที่ต้องการคุณภาพมากที่สุด
ด้านราคา GPT-5.2 อยู่ที่ $1.75/1M input tokens และ $14/1M output tokens พร้อมส่วนลด cached input 90% ส่วน gpt-5.2-pro สูงกว่ามาก (input $21 และ output $168 ต่อ 1M tokens) แต่ OpenAI ระบุว่าแม้ต้นทุนต่อโทเคนสูงขึ้น ต้นทุนในการได้คุณภาพระดับเดียวกัน อาจถูกลงจาก token efficiency ที่ดีขึ้น โดยเฉพาะงานแบบ agentic ครับ
สรุปแบบคนทำงาน GPT-5.2 ดีขึ้นตรงที่ทำงานจบ
ถ้าจะสรุปให้สั้นแบบใช้งานได้ทันที GPT-5.2 ต่างจากรุ่นก่อนใน 3 แกนหลัก แกนแรกคือ งานอาร์ติแฟกต์ อย่างสไลด์และสเปรดชีตที่ดูเป็นมืออาชีพขึ้น ไม่ใช่แค่ร่างสวย ๆ แต่เริ่มเป็นงานที่เอาไปใช้งานต่อได้ แกนที่สองคือ ความเสถียร ทั้งความมั่วที่ลดลง และความสามารถในการอ่านยาว/เชื่อมข้ามบริบทได้ดีกว่าเดิม แกนที่สามคือ ความเป็นเอเจนต์ ใช้เครื่องมือได้แน่นขึ้น ทำงานหลายขั้นตอนได้ครบขึ้น ซึ่งเป็นเงื่อนไขสำคัญของการทำเวิร์กโฟลว์ end-to-end ครับ
และนี่คือ อัปเดต GPT-5.2 เทียบรุ่นก่อน มีอะไรใหม่ และดีขึ้นตรงไหนบ้าง ตัวชี้วัดเหล่านี้ไม่ได้แค่บอกว่า GPT-5.2 ฉลาดขึ้น แต่กำลังชี้ให้เห็นว่า AI เริ่มทำงานที่เคยต้องใช้ผู้เชี่ยวชาญมนุษย์ได้จริงมากขึ้น ทั้งในเชิงคุณภาพ ความเสถียร และการคิดหลายขั้นตอนครับ ทุกวันนี้เทคโนโลยีไปไกลมากขึ้น ถ้าเราใช้อย่างถูกต้องก็จะสามารถสร้างประโยชน์ให้เรามากมายมหาศาลครับ ทั้งด้านการทำงาน และในชีวิตประจำวัน แต่หากใช้ผิดวิธีก็จะเกิดโทษได้ครับ
ผมหวังว่าทุกคนจะนำการพัฒนาของเทคโนโลยีและบทความนี้ไปใช้ให้เกิดประโยชน์ ไม่มากก็น้อยนะครับ ฝากติดตามบทความด้านการใช้ AI แบบนี้ด้วยนะครับ หรือใครอยากให้นำ AI ตัวไหนมาเล่าให้ฟัง สามารถคอมเมนต์บอกกันได้เลยครับ
สำหรับนักอ่านที่ชอบ และ อยากอ่านบทความเกี่ยวกับการตลาด, Data และ AI เพิ่มเติม สามารถติดตามได้จาก เพจการตลาดวันละตอน รวมไปถึง Twitter Instagram YouTube ของการตลาดวันละตอนได้เลยนะครับ แล้วพบกันใหม่ในบทความหน้าครับ
Source