ในฐานะที่เป็นคนเขียนบทความยาวๆ เกือบทุกวันบนเว็บการตลาดวันละตอน สิ่งที่ผมแคร์เวลาเลือกเครื่องมือ AI มาช่วยงานไม่ใช่ว่ามันทำคะแนนสอบได้กี่เปอร์เซ็นต์หรอกครับ แต่คือมันรักษา Mood และ Tone ของผมได้ตลอดบทความยาวๆ มั้ย และมันจะ “มั่ว” ใส่ผมตอนไหนบ้าง
เพราะจากการที่ Anthropic เพิ่งปล่อย Claude Opus 4.8 ออกมาเมื่อวันที่ 28 พฤษภาคม 2026 ห่างจาก Opus 4.7 แค่ราวๆ 6 สัปดาห์ จุดที่เขาเลือกชูเป็นพระเอกกลับไม่ใช่ “เก่งขึ้นกี่เปอร์เซ็นต์” แต่เป็น “โกหกน้อยลงกี่เท่า” และผมว่านี่แหละคือประเด็นที่นักการตลาดอย่างเราควรหยุดอ่านให้จบ เพราะมันคือบทเรียนเรื่อง Brand Positioning ที่ตรงกับสิ่งที่กำลังเกิดในตลาดสินค้าทั่วไปเป๊ะๆ
Why Now ทำไม Anthropic ต้องรีบออก 4.8 ทั้งที่ 4.7 เพิ่งออกไม่นาน
ปี 2026 เป็นปีที่วงการ AI เข้าสู่ยุค Agentic อย่างเต็มตัว คือ AI ไม่ได้แค่ตอบแชตอีกต่อไป แต่สามารถทำงานเองได้ยาวๆ เรียกเครื่องไม้เครื่องมือเอง แก้ error เอง รันไปหลายชั่วโมงโดยไม่ต้องมีคนคุม และในสนามนี้คู่แข่งหายใจรดต้นคอกันหมด ตั้งแต่ GPT-5.5 ของ OpenAI ที่ออกเดือนเมษายน และ Gemini 3.5 ของ Google
ที่น่าสนใจคือ Opus 4.8 ไม่ได้มาแบบกระโดดข้ามรุ่น แต่มาแบบ “เก็บงานที่ค้างไว้ให้เนียนขึ้น” Anthropic เองยอมรับว่ารุ่นนี้ไปแก้ปัญหาที่เจอใน 4.7 อย่างเรื่อง Comment ใน Code ที่เยอะเกินเหตุ และปัญหาการเรียก Tool ที่บางทีข้ามขั้นตอนที่ควรเรียก
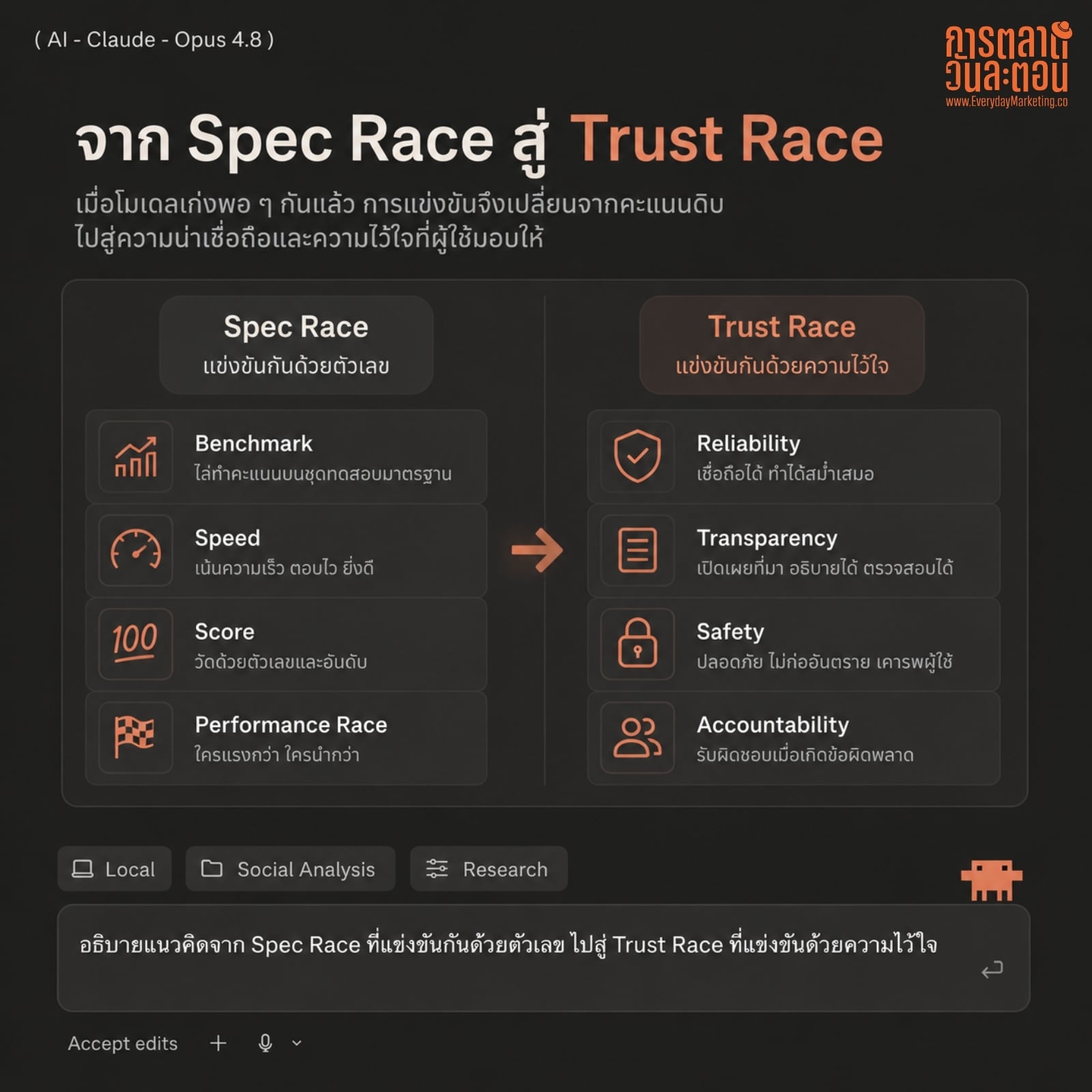
รู้มั้ยครับว่าการ “เก็บงานให้เรียบร้อย” แบบนี้แหละที่บอกได้ว่าบริษัทกำลังเปลี่ยนเกมจากการแข่ง Spec ตัวเลขเดิมๆ ไปสู่การแข่งเรื่องความน่าเชื่อถือในการใช้งานจริง
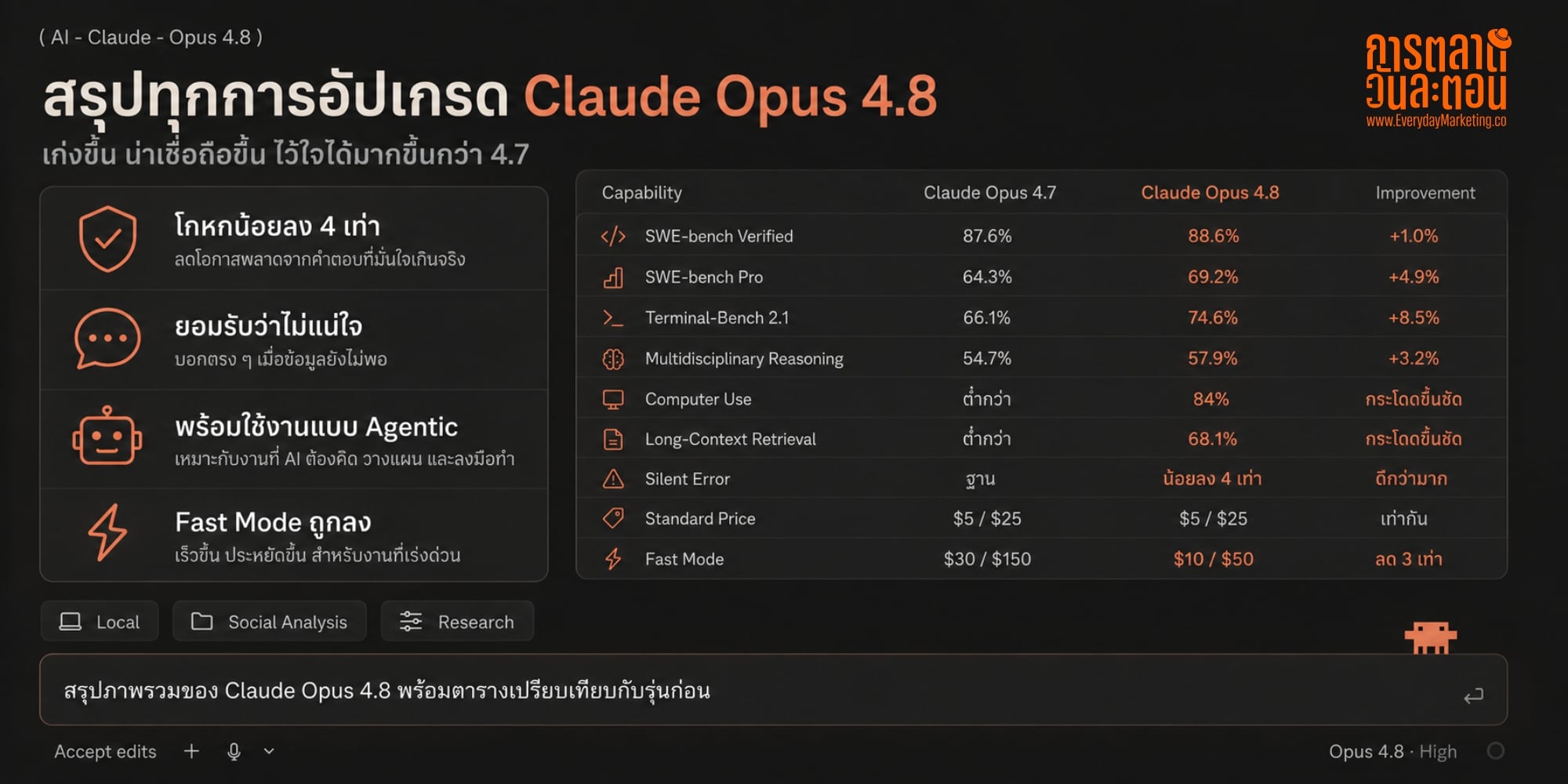
ตารางเปรียบเทียบ Claude Opus 4.8 กับ 4.7
มาดูตัวเลขกันก่อนว่าขยับไปแค่ไหน ตัวเลขทั้งหมดนี้มาจาก System Card และเอกสารทางการของ Anthropic
มิติ Opus 4.7 Opus 4.8 SWE-bench Verified (แก้ Bug จริงบน GitHub) 87.6% 88.6% SWE-bench Pro (โจทย์ Coding ยากกว่า) 64.3% 69.2% Terminal-Bench 2.1 (งานสาย Command Line) 66.1% 74.6% Multidisciplinary Reasoning ใช้ Tool 54.7% 57.9% Computer Use (Online-Mind2Web) ต่ำกว่า 84% Long-Context Retrieval ที่ 1M Token ต่ำกว่า 68.1% โอกาสปล่อย Code ที่มีข้อบกพร่องผ่านไปเงียบๆ ฐาน น้อยลง 4 เท่า ราคา Standard (Input/Output ต่อล้าน Token) $5 / $25 $5 / $25 ราคา Fast Mode (Input/Output ต่อล้าน Token) $30 / $150 $10 / $50
จะเห็นว่าฝั่ง Benchmark ขยับขึ้นแบบ “ก้าวขึ้นบันได” ไม่ใช่ “กระโดด” ตัวที่ขยับเยอะคือพวกงานยากๆ และงาน Agent ระยะยาว ส่วนงานพื้นฐานทั่วไปต่างกันไม่กี่เปอร์เซ็นต์
แต่จุดที่ผมว่าน่าสนใจที่สุดในตารางนี้กลับเป็น 2 บรรทัดล่างสุดครับ
3 จุดเปลี่ยนจริงที่ไม่ได้อยู่ในคะแนนสอบ
1. ราคาเท่าเดิม แต่ของดีขึ้น
Opus 4.8 ออกมาที่ราคา Standard เท่ากับ 4.7 เป๊ะ คือ 5 ดอลลาร์สำหรับ Input และ 25 ดอลลาร์สำหรับ Output ต่อล้าน Token แปลว่าใครที่ใช้ 4.7 อยู่แล้วได้ Performance เพิ่มฟรี ไม่ต้องจ่ายแพงขึ้นเลย
ส่วนที่ลดราคาแรงคือ Fast Mode หรือโหมดที่ผลิต Token เร็วขึ้นราว 2.5 เท่า ราคาลดจาก 30/150 ดอลลาร์ เหลือ 10/50 ดอลลาร์ ถือเป็นการลด 3 เท่า ทำให้งานที่ต้องการความเร็วสูงและทำซ้ำเยอะๆ มีต้นทุนที่จับต้องได้มากขึ้น ในมุมนักการตลาดที่อยากเอา AI ไปฝังในระบบ Automation นี่คือสัญญาณว่าการรันงานปริมาณมากกำลังถูกลงเรื่อยๆ
2. ความซื่อสัตย์กลายเป็น Feature
อันนี้คือหัวใจของทั้งหมดครับ Anthropic บอกว่า Opus 4.8 มีโอกาสปล่อยให้ Code ที่มีข้อบกพร่องผ่านไปโดยไม่เตือนน้อยกว่า 4.7 ถึง 4 เท่า และทีม Alignment รายงานว่าพฤติกรรมหลอกหรือมั่วลดลงอย่างมีนัยสำคัญ
แปลเป็นภาษาคนคือมันกล้ายอมรับว่า “ไม่แน่ใจ” หรือ “อันนี้ทำไม่ได้” มากขึ้น แทนที่จะเดาแล้วตอบแบบมั่วๆ ด้วยความมั่นใจ ซึ่งในยุคที่ AI ทำงานเองยาวๆ โดยไม่มีคนคุม การที่มัน Flag ความไม่แน่ใจให้เราเห็นมีค่ามากกว่าการเก่งขึ้นอีก 1-2% เพราะ Error ที่หลุดไปเงียบๆ ในงานที่รันอัตโนมัติ ราคาแพงกว่าโมเดลที่เก่งน้อยกว่านิดหน่อยแต่ยอมบอกเราว่ามันไม่แน่ใจอะไรบ้าง
3. เก่งเรื่อง Agent และ Computer Use ขึ้นชัด
Anthropic เคลมว่า Opus 4.8 เป็นโมเดลสาย Computer Use และ Browser Agent ที่แข็งที่สุดเท่าที่เคยทดสอบมา ทำได้ 84% บน Online-Mind2Web ซึ่งกระโดดขึ้นชัดจากทั้ง 4.7 และ GPT-5.5 ใครที่สนใจว่า AI เริ่มทำงานออกแบบและคุมหน้าจอแทนเราได้แค่ไหน ผมเคยเขียนเรื่อง Claude Design กับ Agentic Design System ไว้ ลองเข้าไปอ่านต่อได้ครับว่าทิศทางกำลังไปทางไหน
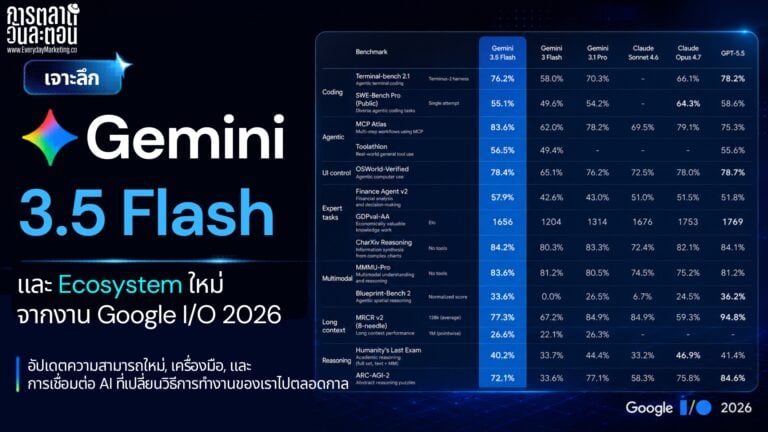
เทียบกับคู่แข่ง GPT-5.5 และ Gemini 3.1 Pro
ทีนี้พอออกนอกบ้าน Anthropic ไปเทียบกับเจ้าอื่น ภาพมันไม่ได้ชนะขาดทุกช่อง และนี่คือจุดที่ผมอยากให้เพื่อนๆ ระวังในการอ่าน Benchmark
มิติ Opus 4.8 GPT-5.5 Gemini 3.1 Pro SWE-bench Pro (Coding ยาก) 69.2% 58.6% ต่ำกว่า Terminal-Bench (งานสาย Command Line) 74.6% 82.7% ต่ำกว่า ARC-AGI-2 (Reasoning โจทย์ใหม่ที่ไม่เคยเห็น) ปานกลาง 85.0% 77.1% OSWorld (คุมคอมพิวเตอร์) แข็ง 78.7% ปานกลาง Throughput ความเร็วผลิต Token ปานกลาง เร็ว เร็วที่สุด (~120 Token/วินาที) จุดเด่นด้านราคา Flat Rate คุ้มตอนงานยาว ระดับกลาง ถูกที่สุดในกลุ่ม
ข้อควรระวังคือ ตัวเลขข้ามค่ายแบบนี้มาจาก Harness หรือชุดทดสอบคนละแบบ และคนละแหล่ง อ่านเป็น “ภาพรวมแนวโน้ม” ได้ แต่อย่าอ่านเป็นการเทียบแบบเป๊ะตัวต่อตัว เพราะแค่เปลี่ยนวิธี Prompt หรือ Setup คะแนนก็ขยับได้แล้ว
สิ่งที่พออ่านออกจากภาพรวมคือ ไม่มีโมเดลไหนชนะทุกช่อง GPT-5.5 ได้เปรียบเรื่องความเร็วและงาน Agent บางสาย กับ Reasoning โจทย์ใหม่ Gemini 3.1 Pro ชนะเรื่องราคาและ Throughput ส่วน Opus 4.8 ได้เปรียบเรื่อง Coding ยากๆ งาน Long-Context และที่สำคัญคือเรื่องความน่าเชื่อถือ ไม่ค่อยมั่ว ซึ่งเป็นเหตุผลที่หลายคนยังเลือกใช้ Claude เป็น Daily Driver แม้ Benchmark ดิบบางตัวจะแพ้
ใครที่อยากเห็นภาพรวมว่าควรเลือกเครื่องมือ AI ตัวไหนมาทำงานสายไหน ผมเคยรวบรวมไว้ในบทความ เครื่องมือ AI สำหรับนักการตลาดปี 2026 แบ่งตามระดับการใช้งานให้แล้ว
4 บทเรียนการตลาดของ Opus 4.8
ทีนี้มาถึงส่วนที่ผมว่าสำคัญกว่าตัวเลขทั้งหมดข้างบน เพราะวิธีที่ Anthropic วางตำแหน่งรุ่นนี้ คือ Case Study เรื่อง Positioning ชั้นดีที่เอามาใช้กับแบรนด์ไทยได้เลย
1. เมื่อ Category โตจนทุกเจ้าเก่งพอกัน สนามรบจะย้ายจาก “เก่งกว่า” ไปสู่ “ไว้ใจได้กว่า”
ตอนนี้ทั้ง 3 ค่ายเก่งพอๆ กันในงานส่วนใหญ่ ต่างกันแค่หลักหน่วยเปอร์เซ็นต์ สภาพแบบนี้เรียกว่า Performance Parity หรือจุดที่ Spec มันตันจนผู้บริโภคแยกไม่ออกแล้วว่าใครเก่งกว่าใคร พอถึงจุดนี้การแข่งที่ตัวเลขจะขายไม่ได้อีกต่อไป Anthropic เลยเลือกชู “ความซื่อสัตย์ ไม่มั่ว” เป็นจุดต่าง แทนที่จะป่าวประกาศว่าคะแนนสอบสูงกว่าใคร
เหมือนตลาดรถยนต์ญี่ปุ่นในไทยที่เลิกแข่งกันที่แรงม้านานแล้ว เพราะรถทุกยี่ห้อก็วิ่งได้หมด แต่ Toyota เลือกชู “ทนทาน ขายต่อได้ราคา ศูนย์บริการเยอะ” ซึ่งก็คือการขายความไว้ใจ ไม่ได้ขาย Performance ตัวเลขเพรียวๆ
2. ราคาเท่าเดิมแต่ของดีขึ้น คือการรักษาฐานลูกค้าที่ฉลาด
การที่ Opus 4.8 ออกมาราคาเท่า 4.7 แปลว่าลูกค้าเดิมไม่มีเหตุผลให้ย้ายค่าย เพราะได้ของดีขึ้นในราคาเดิม นี่คือกลยุทธ์ลด Switching Incentive ที่แบรนด์ Subscription ในไทยใช้บ่อยครับ เช่นค่ายมือถือที่อัปสปีดเน็ตให้ลูกค้าเก่าโดยไม่ขึ้นราคา เพื่อไม่ให้ลูกค้ามีข้ออ้างย้ายไปหาคู่แข่ง
3. หา Niche ที่ตัวเองชนะ แล้วเล่าให้ดังกว่าจุดที่ตัวเองแพ้
Anthropic รู้ว่าตัวเองแพ้ GPT-5.5 ในบางช่อง เขาเลยไม่ไปเล่าตรงนั้น แต่เลือกที่จะเล่าเรื่อง Coding ยากๆ Long-Context และความน่าเชื่อถือที่ตัวเองชนะ บทเรียนสำหรับนักการตลาดคือแบรนด์ไม่จำเป็นต้องชนะทุกเรื่อง แค่ต้องรู้ว่าตัวเองชนะเรื่องไหน แล้วโฟกัสเรื่องนั้นให้ดังที่สุด
4. ในยุค Automation ต้นทุนของการ “โม้เกินจริง” แพงขึ้นเรื่อยๆ
ที่ Anthropic เดิมพันว่าความไว้ใจสำคัญกว่าความเก่ง เพราะในงานที่ AI รันเองยาวๆ การมั่วครั้งเดียวสร้างความเสียหายที่มองไม่เห็นจนกว่าปัญหาจะบานปลาย หลักการนี้ตรงกับการสร้างแบรนด์เป๊ะ ยิ่งผู้บริโภคพึ่งพา AI ในการหาข้อมูลและตัดสินใจมากขึ้น การที่แบรนด์โม้เกินจริงแล้วถูกจับได้จะยิ่งสร้างความเสียหายหนักครับ เพราะพฤติกรรมการค้นหาของคนกำลังย้ายจากการพิมพ์หาใน Google ไปถาม Generative AI ตรงๆ ผมเคยเขียนเรื่อง การทำ GEO ให้แบรนด์ไปโผล่บนคำตอบของ AI ไว้ ซึ่งโลกแบบนั้นแบรนด์ที่ข้อมูลตรงและไว้ใจได้จะได้เปรียบมาก
สรุปบทเรียนที่นักการตลาดจำเป็นต้องรู้จาก Opus 4.8
ถ้าให้สรุปสั้นๆ Claude Opus 4.8 ไม่ใช่การเก่งแบบกระโดดสูง แต่เป็นการ “เก็บงานให้เนียน” บวกกับการเดิมพันครั้งใหญ่ว่าในยุค Agentic ความไว้ใจได้มีค่ากว่าความเก่งโดยตัวเลขคะแนนเท่านั้น
ส่วนตัวเลขที่เพื่อนๆ ควรจำติดตัวไปคือ Benchmark งานยากขยับขึ้นจริง 4-8% ราคา Standard เท่าเดิมที่ 5/25 ดอลลาร์ Fast Mode ถูกลง 3 เท่า และโอกาสที่มันจะปล่อยข้อผิดพลาดผ่านไปเงียบๆ ลดลง 4 เท่า
แต่บทเรียนที่ทรงพลังที่สุดไม่ได้อยู่ที่ตัวเลขครับ แต่มันอยู่ที่วิธีคิด เมื่อสินค้าของคุณเก่งพอๆ กับคู่แข่งจนลูกค้าแยกไม่ออกแล้ว การไล่แข่ง Spec ต่อไปจะเปลืองแรงเปล่า สิ่งที่ควรทำคือถามตัวเองว่าอะไรคือจุดที่ทำให้ลูกค้า “ไว้ใจ” คุณมากกว่าคนอื่น แล้วเทหมดหน้าตักไปกับการทำสิ่งนั้น
เพราะในวันที่ทุกแบรนด์เก่งไม่ต่างกันมาก คนที่ลูกค้าจะเลือกไม่ใช่คนที่เก่งที่สุด แต่คือคนที่ไว้ใจได้มากที่สุด และถ้าคุณยังไม่เริ่มสร้างความไว้ใจนั้นตั้งแต่วันนี้ คุณกำลังทิ้งโอกาสที่สำคัญที่สุดของยุคนี้ไปอย่างน่าเสียดายครับ