Locality Sensitive Hashing หรือที่รู้จักกันในชื่อย่อว่า LSH เป็นอัลกอริทึมลับที่เหมือนเป็นทางลัดในการวิเคราะห์ข้อมูล ซึ่งช่วยเพิ่มความเร็วในการค้นหาข้อมูลขนาดใหญ่ (Big Data) โดยการลดขอบเขตการค้นหาให้แคบลง ซึ่งตัวอัลกอริทึมนี้มีความสามารถในการประมาณค่าความคล้ายคลึงระหว่างข้อมูลที่มีมิติสูง (High-dimensional data) ทำให้อัลกอริทึมนี้เหมาะอย่างยิ่งสำหรับการแก้ปัญหาการค้นหาข้อมูลที่ใกล้เคียงที่สุด (Nearest Neighbor Search) ได้อย่างมีประสิทธิภาพ
พวกเราคงเคยมีข้อสงสัยกันว่า,, เพราะอะไรบาง Contents ที่เราโพสต์ลง Social Media แต่ละแพลตฟอร์มมีอัตราการมองเห็นหรือการขึ้น New Feeds และถูกพบเจอที่ไม่เท่ากัน ทั้งที่เนื้อหาก็เป็นเนื้อหาเดียวกัน หรือใกล้เคียงกัน อัลกอริทึมอะไรที่อยู่เบื้องหลังความต่างของผลลัพธ์เหล่านี้ และคำถามที่สำคัญที่สุดก็คือเราจะจัดการกับระบบเหล่านี้อย่างไรเพื่อเพิ่มประสิทธิภาพการเข้าถึงผู้ชมบนของเราให้ได้ยอดตามที่ต้องการ
วันนี้นิกจะพาทุกท่านไปทำความเข้าใจถึงความหมายของ LSH อีกหนึ่งอัลกอริทึมที่อยู่เบื้องหลังกระบวนการข้อหาข้อมูลที่เป็น Big Data เพื่อมาแสดงผลบนหน้าฟีดใหม่ และตัวอย่างการใช้งานเพื่อเพิ่มประสิทธิภาพการเข้าถึงของผู้ชมที่น่าสนใจกันค่ะ 😊🙂
และแถม!! สำหรับท่านใดที่หลังจากอ่านเรื่องราวของการตลาดสำหรับผู้ใช้รถไฟ แล้วได้แรงบันดาลใจอยากทดลองเล่นกับ Computer Vision AI เพื่อเอาไปใช้งานกับลูกค้าของตัวเอง => เราจะมาลองทำไปพร้อมๆ กันในส่วนท้ายของบทความ ค่ะ ^^
Locality Sensitive Hashing: LSH คืออะไร?
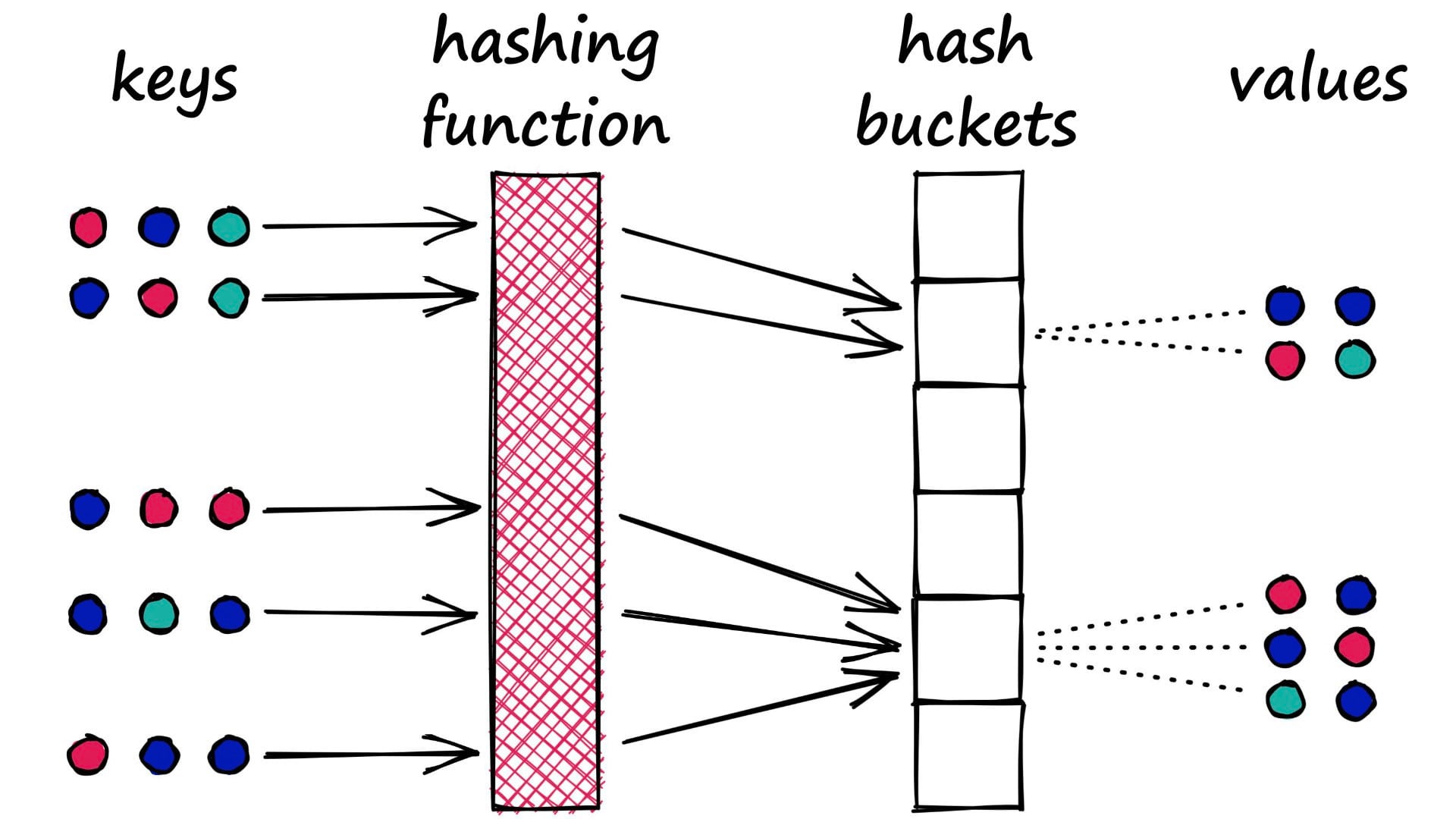
🥳🤓 ต่อไปนี้เราจะเรียก Locality Sensitive Hashing ด้วยชื่อเล่นของเขาว่า “LSH” นะคะ^^ LSH เป็นเทคนิคที่ออกแบบมาเพื่อแก้ปัญหาการค้นหาข้อมูลที่ใกล้เคียงที่สุด (Nearest Neighbor Search) ในชุดข้อมูลที่มีมิติสูง โดยไม่จำเป็นต้องมีขั้นตอนการเรียนรู้ (learning process) และสามารถรักษาข้อมูลเชิงโครงสร้างได้อย่างมีประสิทธิภาพ ซึ่งช่วยลดความซับซ้อนในการค้นหาและเพิ่มความเร็วในการดำเนินการ เป็นทางออกของปัญหาที่พบได้บ่อยในงานวิเคราะห์ข้อมูล เช่น การค้นหาภาพที่คล้ายกันในฐานข้อมูลรูปภาพขนาดใหญ่ การจับคู่อัลกอริทึมในงานประมวลผลสัญญาณเสียง รวมถึงเป็นอัลกอริทึมการค้นหาที่ใช้ในระบบ New Feed
โดย LSH ใช้ ฟังก์ชันแฮช (Hash Functions) ที่ออกแบบมาเพื่อให้ข้อมูลที่มีความคล้ายคลึงกันมีแนวโน้มที่จะถูกแฮชไปยังบัคเก็ตเดียวกันหรือใกล้เคียงกัน ซึ่งเป็นหลักการพื้นฐานที่ทำให้ LSH สามารถลดขอบเขตการค้นหาและเพิ่มความเร็วในการประมวลผลได้,,
วิธีการทำงานของอัลกอริทึม LSH ในการค้นหาข้อมูล
หลังจากที่เรารู้ว่า LSH ใช้หลักการของการแฮช (hashing) เพื่อทำให้การค้นหาข้อมูลที่ใกล้เคียงที่สุด (nearest neighbor search) เป็นไปได้อย่างรวดเร็วและมีประสิทธิภาพ ในส่วนนี้เราจะลงลึกถึงกระบวนการทำงานของ LSH โดยอธิบายวิธีการทำงานของฟังก์ชันแฮช การจัดการบัคเก็ต และขั้นตอนการทำงานที่สำคัญกันค่ะ
🤗 ฟังก์ชันแฮช (Hash Functions) ใน LSH
Hash Functions ใน LSH เป็นเครื่องมือสำคัญที่ใช้ในการแปลงข้อมูลจากเวกเตอร์ที่มีมิติสูงให้เป็นค่าที่มีมิติต่ำกว่า ซึ่งเป็นกระบวนการที่ทำให้ข้อมูลสามารถถูกจัดเก็บและค้นหาได้อย่างมีประสิทธิภาพ
source: https://www.pinecone.io/learn/series/faiss/locality-sensitive-hashing/
1. การแปลงข้อมูลที่มีมิติสูง (High-Dimensional Data):
ข้อมูลที่มีมิติสูงอาจประกอบด้วยหลายคุณสมบัติ เช่น ภาพที่อาจถูกแทนด้วยเวกเตอร์ที่มีหลายร้อยหรือหลายพันค่า ซึ่งทำให้การค้นหาและประมวลผลข้อมูลเหล่านี้มีความซับซ้อนมากขึ้น
ฟังก์ชันแฮชใน LSH ถูกออกแบบมาเพื่อลดมิติของข้อมูลเหล่านี้ โดยการแปลงเวกเตอร์ข้อมูลที่มีมิติสูงให้เป็นค่าที่มีมิติต่ำกว่า เช่น การใช้ฟังก์ชันแฮชแบบสุ่ม (randomized hash functions) ที่สามารถทำให้ข้อมูลที่คล้ายกันถูกแฮชไปยังค่าที่คล้ายกันในมิติต่ำกว่า
2. การทำให้ข้อมูลคล้ายกันอยู่ในบัคเก็ตเดียวกัน:
ตัวอย่างเช่น หากมีข้อมูลสองชุดที่มีความคล้ายคลึงกันในหลายคุณสมบัติ ฟังก์ชันแฮชจะพยายามทำให้ข้อมูลทั้งสองถูกแฮชไปอยู่ในบัคเก็ตเดียวกัน ซึ่งจะทำให้การค้นหาข้อมูลเหล่านี้เป็นไปได้อย่างรวดเร็ว
จุดประสงค์ของการใช้ฟังก์ชันแฮชใน LSH คือการเพิ่มโอกาสที่ข้อมูลที่คล้ายกันจะถูกแฮชให้อยู่ในบัคเก็ตเดียวกัน หรือใกล้เคียงกันในพื้นที่แฮช ซึ่งจะช่วยลดความซับซ้อนในการค้นหาข้อมูลที่ใกล้เคียงที่สุด
🙋♀️Buckets และ Collisions
เมื่อข้อมูลที่เราจะทำ Locality Sensitive Hashing ถูกแฮชด้วย Hash Functions ข้อมูลเหล่านั้นจะถูกจัดเก็บลงใน “Buckets” ซึ่งเป็นกลุ่มที่ Hash Functions กำหนดให้ ข้อมูลในบัคเก็ตเดียวกันจะถูกพิจารณาว่ามีโอกาสที่จะใกล้เคียงกันในแง่ของคุณสมบัติที่ถูกใช้ในการแฮช
1. การจัดเก็บข้อมูลในบัคเก็ต (Buckets):
ข้อมูลที่ถูกแฮชด้วยฟังก์ชันแฮชจะถูกจัดเก็บในบัคเก็ตตามค่าที่แฮชออกมา เช่น หากเรามีบัคเก็ต 10 บัคเก็ต ข้อมูลที่ถูกแฮชด้วยค่าแฮช 3 จะถูกจัดเก็บในบัคเก็ตที่ 3
การจัดข้อมูลในบัคเก็ตเช่นนี้ช่วยให้การค้นหาข้อมูลที่คล้ายกันทำได้เร็วขึ้น เพราะเมื่อเราต้องการค้นหาข้อมูลที่ใกล้เคียง เราสามารถเริ่มค้นหาจากข้อมูลในบัคเก็ตเดียวกันก่อน
2. Collisions และการเพิ่มประสิทธิภาพในการค้นหา:
ยิ่งข้อมูลที่คล้ายกันถูกแฮชให้อยู่ในบัคเก็ตเดียวกันมากเท่าใด ความแม่นยำในการค้นหาข้อมูลที่ใกล้เคียงก็จะยิ่งเพิ่มขึ้น ทำให้ LSH เป็นอัลกอริทึมที่เหมาะสมสำหรับการค้นหาข้อมูลในชุดข้อมูลขนาดใหญ่
Collisions ในที่นี้หมายถึงการที่ข้อมูลหลายชุดถูกแฮชไปยังบัคเก็ตเดียวกัน ซึ่งใน LSH ถือว่าเป็นเรื่องที่ดี เนื่องจาก Collisions ระหว่างข้อมูลที่คล้ายกันจะช่วยให้การค้นหาข้อมูลที่ใกล้เคียงกันทำได้เร็วขึ้น
🏃♀️🏃♀️ ขั้นตอนการทำงานของ Locality Sensitive Hashing
เมื่อเราเข้าใจหลักการของการ Hashing แล้วเรามาดูต่อกันในกันในส่วนของขั้นตอนการทำงานของ LSH หลักแบบคร่าวๆ ดังนี้ค่ะ
1. การแปลงข้อมูล (Data Transformation):
ขั้นตอนแรกของ LSH คือการแปลงข้อมูลที่มีมิติสูงให้เป็นค่าที่แฮชด้วยฟังก์ชันแฮชที่เหมาะสม การแปลงนี้ช่วยรักษาความคล้ายคลึงระหว่างข้อมูลในขณะที่ลดมิติของข้อมูลลง การลดมิตินี้ทำให้การจัดเก็บและการค้นหาข้อมูลมีประสิทธิภาพมากขึ้น
2. การรักษาความคล้ายคลึง (Similarity Preservation):
การรักษาความคล้ายคลึงเป็นส่วนสำคัญของ LSH ซึ่งช่วยให้ข้อมูลที่คล้ายกันยังคงอยู่ใกล้เคียงกันในพื้นที่แฮช ความสามารถในการรักษาความคล้ายคลึงนี้ทำให้ LSH สามารถระบุข้อมูลที่ใกล้เคียงที่สุดได้อย่างรวดเร็ว โดยไม่จำเป็นต้องค้นหาข้อมูลทั้งหมดในชุดข้อมูล
😃🙂 ซึ่งอ่านมาถึงตรงนี้แล้ว เชื่อว่าหลายท่านคงเกิดคำถามว่า ถ้า LSH แฮชข้อมูลที่คล้ายกันให้อยู่ใน Buckets เดียวกันแล้ว แพลตฟอร์มจะแน่ใจได้อย่างไรว่าการเลือกข้อมูลเหล่านั้นมาขึ้นเป็นเนื้อหาใหม่ในฟีดจะตรงกับความสนใจของผู้ใช้จริงๆ เพราะถ้าแค่จัดกลุ่มข้อมูลที่คล้ายกันให้อยู่ใน Buckets เดียวกัน การคัดสรรข้อมูลให้ตรงใจผู้ชมก็อาจยังไม่สมบูรณ์ใช่ไหมคะ
เพราะฉะนั้น เรามาทำความเข้าใจกันต่ออีกนิดค่ะว่า การนำ LSH มาประยุกต์ใช้กับระบบจัดการฟีดเนื้อหาไม่ใช่แค่เรื่องของการแฮชข้อมูลให้ถูกต้อง แต่ยังต้องมีการวิเคราะห์และประมวลผลเพิ่มเติมเพื่อให้แน่ใจว่าฟีดที่แสดงจะตรงกับความสนใจของผู้ใช้และเพิ่มประสบการณ์การใช้งานที่ดีขึ้น ซึ่งมีหลายขั้นตอนที่สามารถนำมาประยุกต์ใช้ได้ และขั้นตอนเหล่านั้นที่เราต้องทำความเข้าใจมีดังนี้ค่ะ
1. Data Aggregation
หลังจากที่ LSH ได้แฮชและจัดกลุ่มข้อมูลที่คล้ายกันให้อยู่ในบัคเก็ตเดียวกันแล้ว ขั้นตอนต่อไปคือการรวบรวมข้อมูลจากแหล่งต่างๆ ในระบบ ไม่ว่าจะเป็นข้อมูลจากการค้นหาก่อนหน้านี้ พฤติกรรมการคลิก หรือเนื้อหาที่ผู้ใช้เคยให้ความสนใจ ข้อมูลเหล่านี้จะถูกใช้เพื่อเสริมความแม่นยำในการเลือกข้อมูลที่จะนำมาแสดงในฟีด เช่น หากผู้ใช้ชอบดูเนื้อหาประเภทหนึ่งเป็นประจำ ระบบอาจเลือกข้อมูลจากบัคเก็ตที่มีความคล้ายคลึงกับเนื้อหานั้นๆ ขึ้นมาแสดงในฟีดใหม่ ซึ่งจะทำให้ฟีดมีความเกี่ยวข้องและตรงกับความสนใจของผู้ใช้มากขึ้น
2. Content Filtering
แม้ว่า LSH จะจัดกลุ่มข้อมูลที่คล้ายกันได้อย่างมีประสิทธิภาพ แต่เพื่อให้แน่ใจว่าข้อมูลที่จะแสดงในฟีดเป็นข้อมูลที่มีคุณภาพสูง และเกี่ยวข้องกับผู้ใช้มากที่สุด ระบบอาจใช้การกรองเนื้อหาเพิ่มเติมโดยอิงจากปัจจัยต่างๆ เช่น ความนิยมของเนื้อหาในขณะนั้น ความใหม่ของข้อมูล หรือการให้คะแนนจากผู้ใช้คนอื่นๆ โดยการกรองเนื้อหาเหล่านี้จะช่วยคัดเลือกข้อมูลจากบัคเก็ตที่ได้รับการจัดกลุ่มโดย LSH ให้นำเสนอเฉพาะเนื้อหาที่ดีที่สุดและมีความเกี่ยวข้องมากที่สุดเพื่อมาแสดงให้เราดูเท่านั้น^^
3. User Behavior Personalization หรือ การปรับแต่งฟีดตามพฤติกรรมของผู้ใช้
นอกจากการจัดกลุ่มข้อมูลแล้ว การปรับแต่งฟีดตามพฤติกรรมการใช้งานของผู้ใช้เป็นสิ่งที่อัลกอริทึมของแต่ละแพลตฟอร์มใช้ โดยฟีดที่แสดงมักมีการปรับเปลี่ยนตามพฤติกรรมการใช้งานของผู้ใช้ เช่น เวลาในการใช้งาน ความถี่ในการเยี่ยมชม และประเภทของเนื้อหาที่คลิกบ่อยๆ โดย LSH จะถูกใช้ร่วมกับการวิเคราะห์พฤติกรรมผู้ใช้สามารถทำให้ระบบเรียนรู้ และปรับแต่งการแสดงผลฟีดให้เหมาะสมกับผู้ใช้แต่ละคนได้มากขึ้น เช่น ถ้าผู้ใช้มักดูวิดีโอเกี่ยวกับการทำอาหาร ระบบก็อาจจะนำเสนอวิดีโอใหม่ๆ ที่เกี่ยวกับการทำอาหารมากขึ้นในฟีด
4. Feedback Loop หรือ การตรวจสอบผลลัพธ์และการปรับปรุง
เพื่อให้ระบบสามารถแสดงฟีดที่ตรงกับความสนใจของผู้ใช้มากที่สุด การตรวจสอบและปรับปรุงผลลัพธ์อย่างต่อเนื่องเป็นสิ่งสำคัญ โดยระบบจะเก็บข้อมูลการตอบสนองของผู้ใช้ เช่น การคลิก การเลื่อนดู หรือการปิดเนื้อหานั้นๆ เพื่อนำข้อมูลเหล่านี้มาปรับปรุงอัลกอริทึมให้ดีขึ้น เช่น หากพบว่าผู้ใช้ไม่สนใจเนื้อหาที่ถูกเลือกมาจาก Buckets หนึ่งบ่อยครั้ง ระบบอาจพิจารณาลดความสำคัญของ Buckets นั้นลงในการแสดงผล New Feed หรือปรับเปลี่ยน Hash Functions เพื่อให้การจัดกลุ่มข้อมูลมีความแม่นยำยิ่งขึ้น
การใช้ งาน Locality Sensitive Hashing เพิ่มประสิทธิภาพการเข้าถึงผู้ชมบน News Feed การนำ LSH มาใช้ในการจัดการฟีดเนื้อหามีความซับซ้อนแต่ให้ผลลัพธ์ที่คุ้มค่า โดยเฉพาะเมื่อสามารถรวมกับเทคนิค อื่นๆ เช่น การกรองเนื้อหา การปรับแต่งตามพฤติกรรมผู้ใช้ และการตรวจสอบผลลัพธ์ ระบบสามารถสร้างฟีดที่มีความเกี่ยวข้องและตอบโจทย์ความต้องการของผู้ใช้ได้อย่างมีประสิทธิภาพ ผ่านการแนะนำเพลงในแอปพลิเคชันสตรีมมิง โดยที่เพลงที่มีลักษณะคล้ายคลึงกับเพลงที่ผู้ใช้ชอบฟังจะถูกเพิ่มในฟีดเพลงที่แนะนำ หรือการแนะนำสินค้าในแพลตฟอร์มอีคอมเมิร์ซ โดยที่สินค้าที่มีความคล้ายคลึงกับสินค้าที่ผู้ใช้เคยดูหรือซื้อจะถูกนำเสนอในฟีดผู้ใช้ ตลอดจนการแนะนำบทความหรือวิดีโอในแอปพลิเคชันข่าว โดยที่บทความที่คล้ายคลึงกับบทความที่ผู้ใช้เคยอ่านจะถูกจัดแสดงในฟีดใหม่
ซึ่งตรงจุดนี้เองค่ะ ที่เราจะใช้ความเข้าใจนี้มาลองตั้งชื่อเนื้อหา ของเราเพื่อให้อัลกอริทึมนี้ Suggest Contents, VDO หรือสินค้าของเราขึ้นบน New Feeds กันค่ะ 🤗🤗
🤗 🐈 มาตั้งชื่อ Contents หลอกอัลกอริทึมกัน^^
Let’s go! “LSH” ทีนี้เรามาลองเล่นสนุกกับการตั้งชื่อของเนื้อหาของเราผ่านแพลตฟอร์มต่างๆ เพื่อให้ Contents, VDO, etc., ของถูกแนะนำบนหน้าฟีดเพิ่มขึ้นกันดูค่ะ
โดยนิกขอยกตัวอย่าง VLOG ที่เห็นได้ชัดในเร็วๆ นี้คือ,,,,VDO นี้เลยค่ะ https://www.youtube.com/watch?v=zl1eWhjzB7wu0026amp;t=93s
ที่อยู่ดีๆ ก็มียอดวิวสูงถึง 51k Views ใน 4 ชั่วโมง ซึ่งชื่อที่ทาง FAROSE ตั้งสำหรับวิดีโอนี้ก็คือ “ไกลบ้าน EP309 ไม่มีไรค่ะตั้งชื่อหลอกอัลกอริทึ่มเฉยๆ ให้นางเซอะเจสท์วิดีโอ ที่จริงคือขอดูเธอหน่อย”
ก็ในเมื่อระบบไม่ยอมแนะนำชื่อรายการสั้นๆ ทาง FAROSE ก็เลยตั้งชื่อยาวๆ หลอก LSH ซะเลย ซึ่งปรากฎว่าได้ผลซะด้วยค่ะ,,
แต่พวกเราในฐานะที่ทำความเข้าใจ LSH เบื้องต้นกันแล้ว เรามาดูกันค่ะว่า ทำไมชื่อแบบนี้ถึงได้ผล ซึ่งเหตุผลก็คือในกรณีของวิดีโอที่มีชื่อยาวๆ แล้วปรากฏใน New Feed บ่อยครั้ง เนื่องจากความยาวของชื่อวิดีโออาจมีบทบาทสำคัญในกระบวนการจัดกลุ่มข้อมูลของ Locality Sensitive Hashing โดยเฉพาะเมื่อเนื้อหาชื่อยาวๆ เหล่านั้นมีลักษณะเฉพาะที่สอดคล้องกับความสนใจของผู้ชมนั่นเองค่ะ
ซึ่ง LSH จะใช้ข้อมูลเหล่านี้เพื่อเพิ่มประสิทธิภาพในการแฮชและจัดกลุ่มข้อมูล ซึ่งช่วยให้วิดีโอที่มีชื่อยาวมีโอกาสปรากฏในฟีดของผู้ชมมากขึ้น โดยเฉพาะเมื่อชื่อวิดีโอนั้นมีความคล้ายคลึงกับสิ่งที่เราดูหรือสนใจมาก่อน โดยมีหลักการดังนี้
1. การจับคู่คำหลักในชื่อวิดีโอ
ชื่อวิดีโอที่ยาวมักจะมีคำหลักหลายคำ ซึ่งอาจครอบคลุมถึงหัวข้อที่หลากหลาย โดย LSH จะใช้คำเหล่านี้ในการแฮชและจัดกลุ่มวิดีโอให้อยู่ในบัคเก็ตเดียวกันกับวิดีโอที่มีคำหลักหรือคีย์เวิร์ดที่คล้ายกัน เช่น หากเราเคยดูวิดีโอที่มีคีย์เวิร์ดเหล่านี้มาก่อน ไม่ว่าจะเป็น “กลับบ้าน,” “เซอเจส,” หรือแม้กระทั่ง “เจอโอที” ระบบจะมองว่าวิดีโอที่มีชื่อยาวซึ่งประกอบด้วยคำเหล่านี้อาจมีความน่าสนใจสำหรับเรา ทำให้มันขึ้นใน New Feed ให้กับคนในวงกว้างมากขึ้นบ่อยๆ
2. การสร้างความหลากหลายในการ Hash
โดยชื่อที่ยาวอาจทำให้ระบบ LSH สามารถจับกลุ่มเนื้อหาในหลายมิติได้ดีขึ้น เพราะแต่ละคำในชื่อวิดีโออาจถูกนำไปจับคู่กับเนื้อหาหรือบัคเก็ตที่แตกต่างกัน ดังนั้น วิดีโอที่มีชื่อยาวอาจปรากฏในหลายบัคเก็ตมากกว่าวิดีโอที่มีชื่อสั้น เช่นกรณีนี้ที่ชื่อวิดีโอมีคำว่า “กลับบ้าน” ระบบอาจจัดกลุ่มวิดีโอนี้กับเนื้อหาที่เกี่ยวกับการเดินทางกลับบ้าน ในขณะเดียวกัน คำว่า “เซอเจส” อาจทำให้วิดีโอนี้ถูกจัดกลุ่มในบัคเก็ตที่เกี่ยวข้องกับการท่องเที่ยวหรือกิจกรรมกลางแจ้ง ทำให้วิดีโอนี้ปรากฏใน New Feed ของเราได้หลากหลายบริบท
3. ความเกี่ยวข้องที่หลากหลาย
ซึ่งชื่อวิดีโอที่ยาวและมีรายละเอียดมากช่วยให้ระบบสามารถประมวลผลและจับคู่ความสนใจที่แตกต่างกันของผู้ใช้ได้ดีขึ้น ตัวอย่างเช่น ชื่อที่มีหลายหัวข้อหรือหลายคีย์เวิร์ดสามารถทำให้วิดีโอปรากฏใน New Feed ของผู้ใช้ที่สนใจหัวข้อต่างๆ ที่ปรากฏในชื่อวิดีโอนั้นได้ และการที่วิดีโอนี้มีชื่อยาวที่ครอบคลุมหลายหัวข้อหมายความว่า LSH จะมีโอกาสมากขึ้นในการจับคู่เนื้อหานี้กับสิ่งที่ผู้ชมเคยสนใจ ทำให้ถูกนำขึ้นมาใน New Feed บ่อยๆ
4. การใช้ชื่อยาวเพื่อเพิ่มโอกาสในการค้นพบ
ส่วนนี้เป็นการพิจารณาจากมุมมองของ Content creators คือชื่อวิดีโอที่ยาวช่วยให้วิดีโอถูกค้นพบได้ง่ายขึ้นในหลายกรณี ไม่ว่าจะเป็นการค้นหาผ่านคำหลักต่างๆ หรือการที่ระบบแนะนำเนื้อหาใน New Feed โดยอิงจากคีย์เวิร์ดในชื่อวิดีโอ
Last but not Least..
ท้ายสุด นิกหวังเป็นอย่างยิ่งค่ะว่าหลายๆ ท่านจะได้ไอเดียในการใช้องค์ความรู้และความเข้าใจในกระบวนการ Search แบบ LSH ไปเป็นไอเดียต่อยอดหรือจุดประกายในการศึกษา Algorithms อื่นๆ เพิ่มเติม..
(ป.ล. แต่ขอแอบกระซิบนะคะว่า การตั้งชื่อยาวๆ ควรตั้งให้สอดคล้องกับความสนใจของกลุ่มเป้าหมายของเราจริงๆ ด้วย เพราะสิ่งเหล่านี้จะมีผลต่อ Bounce rate อีกทีค่ะ)
และนอกจาก LSH แล้ว ยังมีอัลกอริทึมอื่นๆ ที่ใช้ในการค้นหาและจัดลำดับข้อมูลในระบบ New Feed หรือระบบที่ต้องการแสดงผลข้อมูลที่ตรงกับความสนใจของผู้ใช้ ซึ่งนิกขอยกตัวอย่างคร่าว แต่จะไม่ลงรายละเอียด (แต่จะไว้กล่าวถึงในบทความหน้า) ดังนี้ค่ะ
Collaborative Filtering เป็นอัลกอริทึมที่ใช้ในการแนะนำข้อมูลโดยอ้างอิงจากความชอบหรือพฤติกรรมของผู้ใช้คนอื่นๆ ที่มีความคล้ายคลึงกัน สมมติว่าผู้ใช้สองคนชอบเนื้อหาคล้ายๆ กัน ระบบจะใช้ข้อมูลนี้เพื่อแนะนำเนื้อหาที่ผู้ใช้หนึ่งอาจสนใจโดยอ้างอิงจากสิ่งที่ผู้ใช้อีกคนชอบ ได้แก่ การแนะนำหนังใน Netflix โดยอิงจากสิ่งที่ผู้ใช้คนอื่นที่มีความสนใจคล้ายกันเคยดู
Content-Based Filtering ใช้ข้อมูลจากเนื้อหาของสิ่งที่ผู้ใช้เคยดูหรือสนใจมาก่อน เพื่อแนะนำเนื้อหาที่คล้ายกัน อัลกอริทึมนี้จะสร้างโปรไฟล์ของผู้ใช้ตามข้อมูลที่เขาชอบ เช่น หากผู้ใช้ชอบอ่านบทความเกี่ยวกับเทคโนโลยี ระบบก็จะแนะนำบทความที่เกี่ยวข้องกับเทคโนโลยีให้ เช่น การแนะนำบทความในฟีดข่าวโดยอิงจากบทความที่ผู้ใช้เคยอ่าน
Hybrid Methods เป็นการรวมเอาวิธีการหลายๆ แบบเข้าด้วยกัน เช่น การรวม Collaborative Filtering และ Content-Based Filtering เพื่อเพิ่มความแม่นยำในการแนะนำเนื้อหา วิธีนี้ช่วยให้สามารถใช้ประโยชน์จากข้อมูลที่มีอยู่ได้อย่างมีประสิทธิภาพมากขึ้น เช่น การแนะนำเพื่อนในโซเชียลมีเดียที่รวมเอาข้อมูลจากการกรองแบบร่วมมือและตามเนื้อหา
Graph-Based Recommendation ใช้โครงสร้างข้อมูลแบบกราฟในการสร้างความสัมพันธ์ระหว่างผู้ใช้และเนื้อหา เช่น การใช้กราฟเพื่อแสดงความสัมพันธ์ระหว่างผู้ใช้ที่มีความสนใจร่วมกัน หรือเนื้อหาที่คล้ายกัน วิธีนี้ช่วยให้ระบบสามารถแนะนำเนื้อหาที่เกี่ยวข้องได้อย่างแม่นยำยิ่งขึ้น ได้แก่ การแนะนำเพลย์ลิสต์เพลงที่คล้ายกันใน Spotify โดยอ้างอิงจากการสร้างกราฟความสัมพันธ์ระหว่างเพลงและผู้ใช้