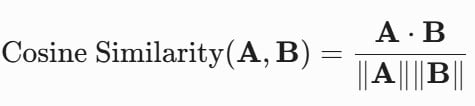สวัสดีค่ะทุกท่าน,, ช่วงนี้นิกสังเกตุเห็นว่าตัวนิกเองเปิด TikTok ทีไร เวลาวาร์ปหายไป 2 ชั่วโมงทุกที ซึ่งเหตุการณ์นี้ไม่เคยเป็นมาก่อน จนกระทั่งช่วงต้นปี 2026 ที่ผ่านมา นิกเลยเริ่มสงสัยว่าทำไมหน้า For You Page (FYP) ของ TikTok ถึงคัดแต่คลิปที่สามารถดึงดูดความสนใจได้ดีขึ้นกว่า TikTok Algorithm แบบเดิม,, เลยเป็นที่มาของการหาข้อมูล ทำ Reverse Engineer เพื่อมาแชร์ให้ทุกท่านทราบในบทความนี้ค่ะ
ซึ่งนิกจะพาทุกคนมาสวมหมวกเป็น Data Scientist และ Marketer ที่จะมาค้นหาความลับเบื้องหลัง Algorithmic Gaze หรือ สายตาอัลกอริทึม ของ TikTok ว่าจากฟังก์ชันคณิตศาสตร์ และโครงสร้าง Big data algorithm นี้กำลังควบคุมสิ่งที่เราเห็นและ(แอบ)ปิดกั้นสิ่งที่เราไม่เห็นอย่างไรบ้างกันค่ะ,, Let’s go (☞゚ヮ゚)☞
#1 จาก Social Graph สู่ High-Dimensional Clustering
ถ้าเรามองย้อนกลับไปในยุค Facebook หรือโซเชียลมีเดียยุคเก่า อัลกอริทึมจะทำงานบนพื้นฐานของ ทฤษฎีกราฟ (Graph Theory) ซึ่งฟีดของเราจะขึ้นอยู่กับโครงสร้างความสัมพันธ์ที่ชัดเจน (Explicit Social Graph) ที่มีผู้ใช้เป็น (Nodes) และมีความเป็นเพื่อนหรือการติดตามเป็นเส้นเชื่อม (Edges) โดยข้อมูลจะไหลไปตาม Graph นี้ ซึ่งขยับตัวค่อนข้างช้า และถูกจำกัดด้วยสังคมในโลกจริงที่เรา Add Friends หรือ กด Follow ไว้ ซึ่งปัญหาคือ สิ่งที่เพื่อนสนใจ อาจไม่ใช่สิ่งที่เราสนใจค่ะ
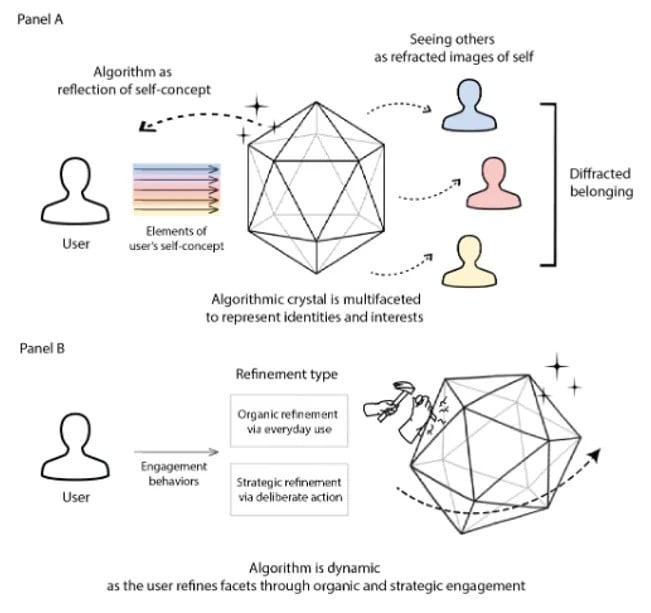
แต่ TikTok ปฏิวัติสิ่งนี้ด้วยการตัดเส้นเชื่อมแบบเดิมทิ้ง แล้วหันมาใช้โมเดล พื้นที่เวกเตอร์หลายมิติ (High-Dimensional Vector Space) แทน หมดยุคตามใจเพื่อน สู่ยุคตามใจฉัน หรือสิ่งที่ฉันอยากเห็นที่แท้ True ด้วย Features เหล่านี้ค่ะ
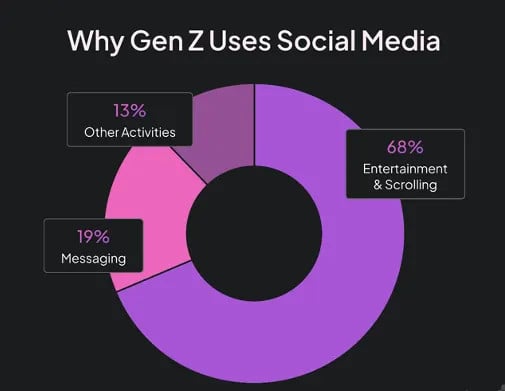
Feature Embedding: ระบบจะแปลงคุณลักษณะของคลิป เช่น คีย์เวิร์ดจาก NLP, แฮชแท็ก, สัญญาณเสียง, แท็กรูปภาพ ให้กลายเป็นเวกเตอร์ตัวเลขที่มีความหนาแน่นที่เรียกว่า Dense VectorsReal-time Behavioral เวกเตอร์: พฤติกรรมการไถจอของเราในทุกๆ วินาที 😂😂 จะถูกบันทึกและแปลงเป็นเวกเตอร์พฤติกรรมของเราแบบละเอียดยิบค่ะ (สมัยก่อนเราจะเห็น GenZ ที่เป็นกลุ่มหลักใน TikTok User แต่ปัจจุบันนี้ไม่ใช่อีกต่อไปแล้วค่ะ)
จากนั้น ระบบจะคำนวณระยะห่างทางคณิตศาสตร์ด้วยสมการความคล้ายคลึงของโคไซน์ (Cosine Similarity) เพื่อจับคู่เราเข้ากับคลิปที่คาดว่าเราน่าจะสนใจ:
เมื่อเวกเตอร์ของเรา (A) ทำมุมแคบเข้าใกล้เวกเตอร์ของเนื้อหา (B) ค่าโคไซน์จะเข้าใกล้ 1 ผลลัพธ์ในเชิง Topology จะทำให้การเกิดสภาวะกลุ่มก้อนสาธารณะหรือ Clustered Publics ที่ดึงเอาคนแปลกหน้าที่ไม่รู้จักกัน แต่กลับมีรสนิยมทางเวกเตอร์ ตรงกัน ให้เข้ามาอยู่ในกลุ่มก้อนข้อมูลเดียวกันทันที เกิดเป็นตัวตนแบบใหม่ที่เรียกว่า Algorithmized Self ค่ะ
#2 Objective Function & Local Maxima ของ TikTok Algorithm
สิ่งสำคัญต่อไปใน TikTok Algorithm ซึ่งเป็นเหตุผลที่ว่าทำไมดราม่า ถึงชนะสาระเสมอ? ทำไมคลิปเต้น คลิปตลก หรือประเด็นดราม่า ถึงไวรัลง่ายกว่าคลิปให้ความรู้ทางการแพทย์หรือสาระวิชาการ
ซึ่งเรื่องนี้ไม่ใช่ความบังเอิญค่ะเพื่อนๆ แต่เกิดจากการที่โมเดลถูกเทรนให้หาจุดที่เหมาะสมที่สุด (Optimization) ผ่าน ฟังก์ชันเป้าหมาย (Objective Function)
โดยเป้าหมายสูงสุดของ TikTok ไม่ใช่การค้นหาความจริงหรือสาระ แต่คือการกักเก็บผู้ใช้ให้อยู่บนแพลตฟอร์มนานที่สุด (Watch Time & Retention Optimization) ถ้าเรานำมาเขียนเป็นสมการคำนวณคะแนนสำหรับการจัดอันดับคลิป (Score) หน้าตาจะออกมาประมาณนี้ค่ะ
โดยที่ w1, w2, w3, w4 คือ ค่าน้ำหนัก (Weights) ที่ TikTok Algorithm กำหนดให้กับพฤติกรรมต่างๆ ค่ะ
ซึ่งเมื่อ AI ทำการคำนวณหาความชันผ่านการทำ Gradient Descent จะพบว่า Content ประเภทดราม่า หรือคตก มีอัตราส่วนการดูจนจบ (Completion Rate) และการดูซ้ำ (Looping) ที่สูงและชันมากในพื้นที่การคำนวณ TikTok Algorithm จึงพาเราที่เป็น User Deep ไปในจุดนั้นทันทีค่ เพราะจุดนั้นคือจุดที่ทำยอดคำนวณได้สูงสุดในพิกัดนั้น หรือที่เรียกว่า Local Maxima (เดี๋ยวนิกอาจจะมีบทความเรื่อง Gradient Descent เพื่อขยายความเพิ่มเติมสำหรับผู้สนใจนะคะ)
ส่วนคลิปสาระที่ถูกต้องแต่น่าเบื่อ มักมีลักษณะเป็นพื้นราบ (Flat Surface) ในมิติการดึงดูดความสนใจ ทำให้อัลกอริทึมไม่เลือกเดินไปในทิศทางนั้น และทำให้ข้อมูลดีๆ ต้องตกลงสู่สภาวะการไร้ตัวตนทางคณิตศาสตร์ (Mathematical Invisibility) ไปอย่างน่าเสียดาย (เพราะฉะนั้นถ้าเพื่อนๆ ยังคงอยากเห็นคลิปที่มีสาระอยู่ก็พยายามดู Content สาระให้จบโดยไม่ปัดผ่านนะคะ)
#3 Deep Learning & Algorithmic Bias
และส่วนต่อไปคือ Deep Learning ที่เป็นเหมือนกล่องดำทาง Algorithm ที่ทุกคนกลัวค่ะ เพราะสิ่งที่พวกเราชาวครีเอเตอร์และนักการตลาดกังวลที่สุดคือ Shadowban หรือการโดนลดการมองเห็นอย่างเงียบๆ ซึ่งมักเกิดขึ้นกับกลุ่มเปราะบาง เช่น กลุ่ม LGBTQ+ หรือผู้พิการ โดยปรากฏการณ์นี้อธิบายในมุมมองของ AI Engineer ได้ด้วย 2 ปัจจัยหลักดังนี้ค่ะ
3.1 Black Box Society: สภาวะกล่องดำ
TikTok เลือกใช้โมเดลประเภท โครงสร้างข่ายประสาทเทียมเชิงลึก หรือ Deep Neural Networks เช่น โครงสร้างโมเดลประเภท Multi-gate Mixture-of-Experts (MMoE) เพื่อประมวลผลความสนใจที่ซับซ้อน โดยโมเดลพวกนี้มี Independent Parameters แทบจะเป็นล้านๆ ตัวที่สัมพันธ์กันแบบไม่เป็นเส้นตรง (Non-linear Multi-layered Systems) ซึ่งสิ่งนี้ทำนายผลได้แม่นยำมากค่ะ แต่ต้องแลกมาด้วยการสูญเสียความสามารถในการอธิบาย (Explainable AI – XAI) หรือพูดง่ายๆ ค่ะว่าเป็น กล่องดำไปเลย ที่ทำให้เราไม่สามารถแกะสูตรย้อนกลับได้ง่ายๆ ว่าทำไมคลิปบางคลิปถึงปลิวหายไปเฉยๆ
3.2 Algorithmic Bias: อคติทางอัลกอริทึม
เมื่อแพลตฟอร์มใช้ AI ในการคัดกรองเนื้อหาอัตโนมัติ (Automated Moderation) ตัวโมเดลมักจะได้รับผลกระทบจาก อคติในข้อมูลที่ใช้ฝึกฝน (Historical / Training Data Bias) หาก Dataset ที่ใช้เทรนมองว่าอัตลักษณ์บางประเภทมีความเสี่ยงสูง Algorithm จะทำการลดคะแนน (Downgrading) ในการแสดงผลบนหน้า FYP โดยอัตโนมัติ ซึ่งนี่คือการกีดกันทางสังคมผ่าน Digital Marginalization ในบริบทของคำว่ามาตรฐานความปลอดภัยค่ะ
#4 Game Theory & Adversarial Adaptation
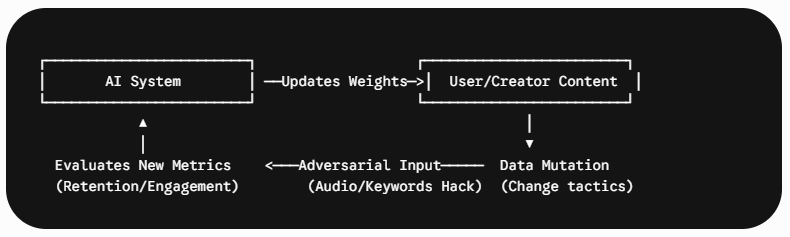
แต่ถึงแม้ว่าระบบจะคุมเกมทั้งหมดไว้ แต่ครีเอเตอร์และนักการตลาดสายเทคพยายามทำสิ่งที่เรียกว่า Reverse Engineering หรือการแกะรอยย้อนกลับเพื่อเดาใจ AI ซึ่งคือสิ่งที่เราทำกันในบทความนี้ค่ะ ด้วยทฤษฎีเกม (Game Theory) และ การปรับตัวแบบปฏิปักษ์ (Adversarial Adaptation)
เพราะในระบบที่มนุษย์เป็นส่วนหนึ่งในวงจร (Human-in-the-loop) สภาวะสมดุลแบบแนช (Nash Equilibrium) จะไม่มีวันเกิดขึ้นจริง และเมื่อ AI อัปเดตค่าน้ำหนัก (Weights) Creators และ Marketers จะทำการทดลองเชิงประจักษ์ (Empirical Testing) เพื่อหาวิธีเรียนรู้ความสัมพันธ์และแก้ไขทันที เช่น
Data Mutation: การเปลี่ยนรูปแบบข้อมูลเข้า เช่น การเปลี่ยนเวลาโพสต์ การเกาะโครงสร้างข้อมูลของคลิปที่เป็นกระแสผ่านการใช้แผ่นเสียงฮิต (Trending Audio) เพื่อดันตัวเองเข้าคลาสเตอร์ขนาดใหญ่Data Masking: เมื่อรู้ว่าระบบคัดกรองคำ (Content Moderation) จะแบนคำบางคำ ครีเอเตอร์จะแฮกระบบด้วยการเลี่ยงบาลี สะกดคำแปลกๆ หรือใช้ภาพสื่อแทน เพื่อหลบเลี่ยงไม่ให้ AI ตรวจจับได้ เช่นตอนนี้ใน RoV ใช้ คำว่า โคดี้ แทนการพูดว่าโค้ด 😎😎 (ซึ่งนิกเข้าไปสิงรอโคดี้ฟรีอยู่เหมือนกันค่ะ 5555+)
และสิ่งเหล่านี้คือพลวัตการปรับตัวร่วมกัน (Co-evolution) ที่ TikTok Algorithm พัฒนา Mathematics Model เพื่อควบคุม ส่วนอีกฝั่งก็พัฒนาความคิดสร้างสรรค์เพื่อแหกกฎ ไล่จับกันไปมาอย่างไม่รู้จบค่ะ
Last but not Least,,
ในมุมมองนิก TikTok Alogorithm ในบริบทสายตาของอัลกอริทึม เป็นความสำเร็จทางคณิตศาสตร์ที่ทำหน้าที่ได้อย่างสมบูรณ์แบบในการกักเก็บความสนใจของผู้ใช้ (Retention)
แต่โจทย์ใหญ่ในอนาคตของคนสร้าง AI และนักการตลาด คือเราจะพัฒนาสถาปัตยกรรมข้อมูลอย่างไรให้ไปไกลกว่าแค่การสร้างผลกำไร แต่สร้างเป็นความยั่งยืนของ Ecosystem เช่น
Multi-Objective Optimization for Fairness: การออกแบบ Loss Function ใหม่ที่ไม่ได้คำนวณแค่ยอด Engagement แต่ใส่ค่าน้ำหนักด้านความหลากหลาย (Diversity Score) และความเท่าเทียมเข้าไปด้วยStochastic Exploration: การใช้กลุ่มอัลกอริทึม Multi-Armed Bandit (MAB) เพื่อกระจายโอกาสให้ผู้ใช้ได้หลุด ออกไปค้นพบเนื้อหาใหม่ๆ นอกคลาสเตอร์เดิมของตัวเอง เพื่อช่วยทลายกำแพงห้องสะท้อนเสียง (Filter Bubbles) และลดความรุนแรงของการแบ่งขั้วในโลกออนไลน์ลงได้ค่ะ