เวลาทำวิจัยการตลาด หลายคนมักโฟกัสไปที่ความท้าทายในการเก็บ Data ให้ได้จำนวนเยอะ ๆ แต่รู้หรือไม่ครับว่าหลุมพรางที่น่ากลัวที่สุดกลับเป็นคำถามที่ว่า “แบบสอบถามของเรา วัดสิ่งที่เราอยากรู้ได้จริง ๆ หรือเปล่า?” โดยเฉพาะเมื่อธุรกิจต้องการวัดสิ่งที่จับต้องไม่ได้อย่าง “ความรู้สึก” หรือ “ความเชื่อใจ” ของผู้บริโภค บทความนี้จะพามาเจาะลึก 2 สถิติในสาย วิจัยการตลาด ที่สำคัญอย่าง EFA และ CFA ซึ่งเปรียบเสมือน “เครื่องตรวจคุณภาพแบบสอบถาม” ที่นักการตลาดสายวิจัยต้องรู้ เพื่อช่วยถอดรหัสโครงสร้างความคิดลูกค้า ยืนยันความแม่นยำของชุดคำถาม และป้องกันไม่ให้ธุรกิจก้าวพลาดเพียงเพราะใช้เครื่องมือที่วัดผลผิดจุดครับ
ในการทำวิจัยการตลาด หลายคนมักคิดว่าความยากที่สุดคือ “การเก็บแบบสอบถามให้ได้เยอะ ๆ” หรือ “หาคนตอบให้ครบตามจำนวน Sample” แต่จริง ๆ แล้ว สิ่งที่ยากกว่านั้นมาก คือการตอบให้ได้ว่า “แบบสอบถามที่เราใช้ มันวัดสิ่งที่เราอยากวัดจริงหรือเปล่า” เพราะในงานวิจัยการตลาด สิ่งที่ธุรกิจอยากรู้มากที่สุด มักไม่ใช่สิ่งที่จับต้องได้ตรง ๆ ครับ
ถ้าเป็นยอดขายเราวัดได้เลย ถ้าเป็นอายุลูกค้าเราก็ดูจากตัวเลขได้เลย แต่สิ่งที่นักการตลาดอยากรู้จริง ๆ มักเป็นเรื่องใน “ความรู้สึก” และ “ความคิด” ของผู้บริโภคครับ เช่น
ลูกค้าเชื่อใจแบรนด์เราหรือไม่
ลูกค้ารู้สึกผูกพันกับแบรนด์แค่ไหน
ลูกค้าพึงพอใจกับประสบการณ์ที่ได้รับหรือเปล่า
ปัญหาคือ สิ่งเหล่านี้ไม่มีหน่วยวัดตรง ๆ ครับ คือเราไม่สามารถเอาไม้บรรทัดไปวัด Brand Trust ได้ และไม่มีเครื่องชั่งที่ชั่ง Customer Loyalty ออกมาเป็นตัวเลขได้เหมือนกัน ซึ่งในทางสถิติ สิ่งเหล่านี้เรียกว่า “ตัวแปรแฝง” หรือ Latent Variable ครับ คำว่า “แฝง” หมายถึง มันมีอยู่จริง แต่เรามองไม่เห็นโดยตรง
ดังนั้น นักวิจัยจึงต้องใช้วิธี “แปลงความรู้สึก” ให้ออกมาอยู่ในรูปของข้อคำถามหลาย ๆ ข้อแทนครับ ยกตัวอย่างเช่น ถ้าเราอยากวัด “Brand Trust” เราอาจสร้างคำถามประมาณนี้
ฉันเชื่อว่าแบรนด์นี้รักษาสัญญา
ฉันมั่นใจในคุณภาพของแบรนด์นี้
ฉันรู้สึกปลอดภัยเมื่อใช้แบรนด์นี้
ฉันเชื่อว่าแบรนด์นี้ซื่อสัตย์ต่อผู้บริโภค
ทีนี้คำถามสำคัญคือ ข้อคำถามเหล่านี้ “วัด Brand Trust จริงหรือเปล่า” หรือจริง ๆ แล้วบางข้ออาจกำลังวัด “ความพึงพอใจ” บางข้ออาจกำลังวัด “ภาพลักษณ์แบรนด์” หรือบางข้ออาจไม่ได้วัดอะไรเลยก็ได้ครับ
นี่แหละครับ คือจุดที่ EFA และ CFA เข้ามามีบทบาทสำคัญมาก เปรียบเสมือน “เครื่องตรวจคุณภาพของแบบสอบถาม” ครับ เปรียบง่าย ๆ เหมือนธุรกิจกำลังสร้างเครื่องมือวัดบางอย่างขึ้นมา แล้ว EFA/CFA ทำหน้าที่ตรวจว่า
เครื่องมือนี้แม่นจริงไหม
วัดถูกเรื่องไหม
ข้อคำถามแต่ละข้อสะท้อนสิ่งเดียวกันจริงหรือเปล่า
เพราะถ้าจุดเริ่มต้นผิด ทุกอย่างหลังจากนั้นก็ผิดหมดครับ ต่อให้เราเก็บแบบสอบถามมาได้ 1,000 ชุด
สิ่งที่ต้องรู้ Latent Variable vs Observed Variable ขั้นแรกสุดของกระบวนการวิจัยคือการทำความเข้าใจว่าเรากำลังจะวัดอะไร ตัวแปรที่น่าสนใจในการตลาดส่วนใหญ่ล้วนเป็นตัวแปรแฝง (Latent Variable) ทั้งนั้น ไม่ว่าจะเป็น Brand Love, Customer Trust, Perceived Value, Service Quality หรือ AI Readiness สิ่งเหล่านี้ไม่มีตัวเลขให้วัดตรง ๆ นักวิจัยจึงต้องสร้างข้อคำถามหลายข้อขึ้นมาเพื่อสะท้อนสิ่งนั้น ซึ่งข้อคำถามเหล่านี้เรียกว่า Observed Variable หรือ Indicator ครับ
ยกตัวอย่างเช่น ถ้าต้องการวัด Brand Trust ก็อาจสร้างคำถามว่า “ฉันเชื่อว่าแบรนด์นี้ซื่อสัตย์” หรือ “แบรนด์นี้รักษาสัญญาที่ให้ไว้กับลูกค้า” ผู้ตอบสามารถให้คะแนนคำถามเหล่านี้ได้ แต่ตัว Brand Trust เองนั้นยังคงมองไม่เห็น เราอนุมานมันจากคำตอบรวมกันเท่านั้น
สิ่งที่ต้องระวังในเชิงธุรกิจคือ ถ้านิยาม Latent Variable ไม่ชัดตั้งแต่แรก ผลวิจัยจะตีความยากมาก ตัวอย่างที่พบบ่อยคือ แบบสอบถาม Customer Experience ที่ปนคำถามเรื่องราคา การจัดส่ง และภาพลักษณ์แบรนด์ไว้ด้วยกัน โดยไม่แยกมิติ สุดท้ายก็ตอบไม่ได้ว่าควรปรับปรุงเรื่องใดก่อน
EFA คืออะไร และทำงานอย่างไร EFA ย่อมาจาก Exploratory Factor Analysis หรือ การวิเคราะห์องค์ประกอบเชิงสำรวจครับ คำว่า Exploratory บ่งบอกชัดเจนอยู่แล้วว่า เราไม่ได้ตั้งสมมติฐานล็อกโครงสร้างไว้ก่อน แต่ปล่อยให้ข้อมูลบอกเองว่า คำถามจำนวนมากเหล่านั้นสามารถรวมกลุ่มเป็นมิติหลักกี่มิติ
ลองนึกภาพว่า ธุรกิจทำแบบสอบถาม 30 ข้อเกี่ยวกับประสบการณ์ซื้อสินค้าออนไลน์ EFA อาจพบว่าในหัวลูกค้า 30 เรื่องนั้นไม่ได้แยกจากกัน แต่รวมเป็น 5 มิติ ได้แก่ ความสะดวกในการสั่งซื้อ ความน่าเชื่อถือของร้านค้า ความรวดเร็วในการจัดส่ง ความคุ้มค่าด้านราคา และการดูแลหลังการขาย
ตัวอย่างแบบชัด ๆ ลองนึกภาพว่า เราทำแบบสอบถามเกี่ยวกับประสบการณ์ซื้อสินค้าออนไลน์ทั้งหมด 20 ข้อ เช่น
เว็บไซต์ใช้งานง่าย
หาสินค้าได้เร็ว
โปรโมชั่นน่าสนใจ
ขั้นตอนจ่ายเงินไม่ซับซ้อน
แอปไม่ค้าง
ราคาคุ้มค่า
ระบบค้นหาสินค้าทำงานดี
ส่วนลดดึงดูดใจ
ร้านค้าน่าเชื่อถือ
กล้ากรอกข้อมูลบัตรเครดิต
เชื่อว่าสินค้าจะได้ของจริง
มั่นใจในการรับประกัน
จัดส่งรวดเร็ว
แพ็กสินค้าดี
แจ้งสถานะการส่งชัดเจน
ติดต่อแอดมินง่าย
ตอบแชทไว
แก้ปัญหาให้รวดเร็ว
คืนสินค้าง่าย
บริการหลังการขายดี
ตอนแรก นักวิจัยอาจยังไม่รู้ครับ ว่า ควรแบ่งเรื่องพวกนี้ยังไงอะไรบ้าง แต่พอเอาข้อมูลไปทำ EFA สิ่งที่เกิดขึ้นคือ โปรแกรมจะดูว่า “ข้อไหนที่คนมักตอบไปในทิศทางเดียวกัน”
เช่น คนที่ให้คะแนนข้อ 1 สูง มักให้ข้อ 2, 4, 5, 7 สูงเหมือนกัน EFA จึงมองว่า 1, 2, 4, 5, 7 น่าจะเป็น “เรื่องเดียวกัน” แล้วมันจะรวมออกมาเป็น Factor หนึ่งครับ ซึ่งนักวิจัยอาจตีความทีหลังว่า Factor นี้คือ “ความสะดวกในการใช้งานระบบ” โดยดูจากข้อคำถาม
ในขณะเดียวกัน EFA อาจพบอีกว่า 9, 10, 11, 13 มักถูกตอบไปในทิศทางเดียวกันเหมือนกัน จึงถูกรวมเป็นอีก Factor หนึ่ง ที่อาจตีความได้ว่า “ความน่าเชื่อถือของร้านค้า”
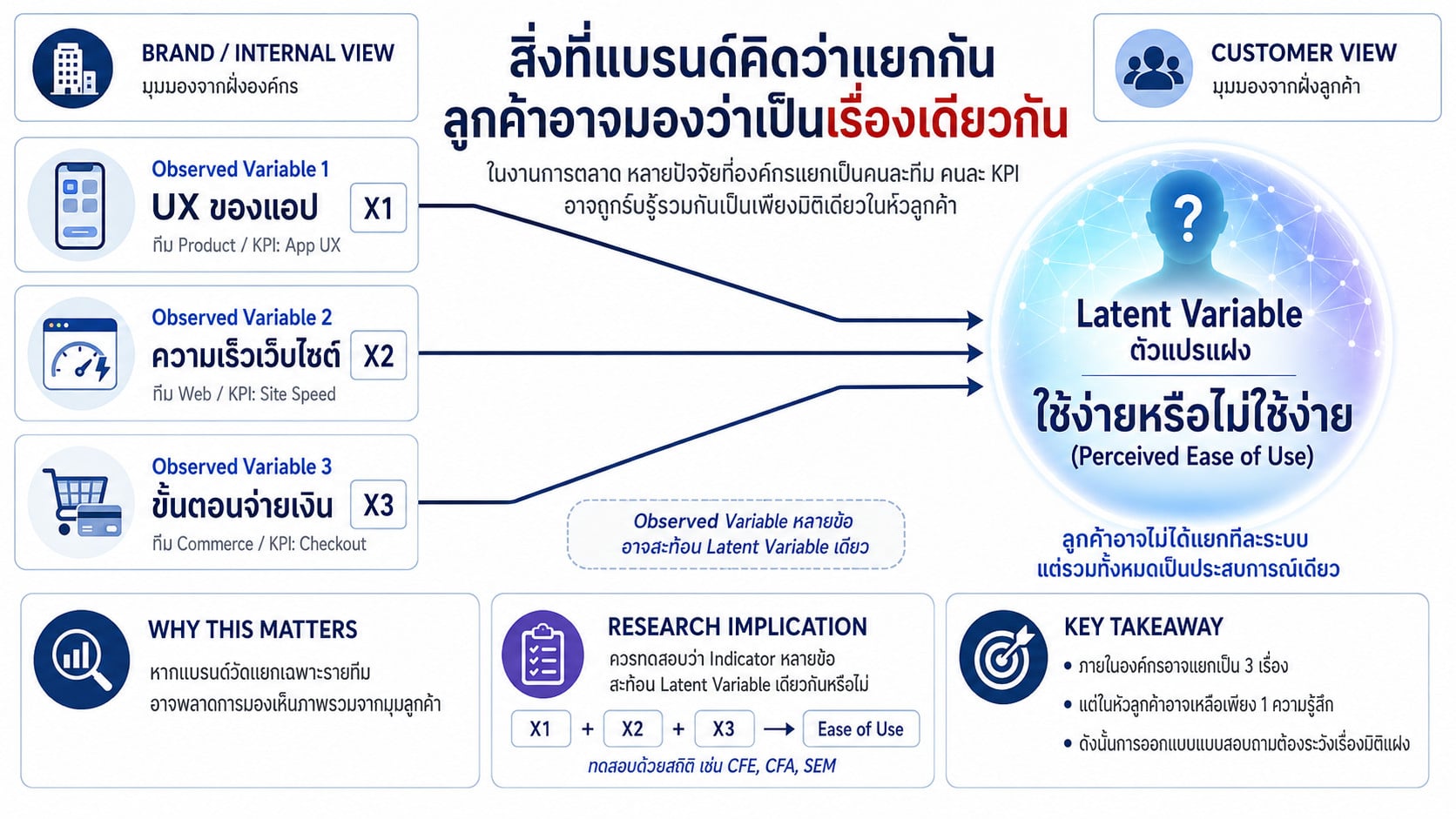
จะเห็นว่า สิ่งสำคัญมากคือ นักวิจัยไม่ได้เป็นคนสั่งว่า ข้อไหนต้องอยู่กลุ่มเดียวกัน แต่ “ข้อมูลของลูกค้า” เป็นคนบอกเองครับ นี่คือเหตุผลที่ EFA ถูกเรียกว่า Exploratory หรือ “เชิงสำรวจ” เพราะเราเข้าไป “ค้นหาโครงสร้างที่ซ่อนอยู่” ในข้อมูล และนี่สำคัญมากในงานการตลาดครับ เพราะหลายครั้ง สิ่งที่แบรนด์คิดว่าเป็นคนละเรื่อง ลูกค้าอาจมองว่าเป็นเรื่องเดียวกันก็ได้
เช่น บริษัทอาจแยกระหว่าง
UX ของแอป
ความเร็วเว็บไซต์
ขั้นตอนจ่ายเงิน
ออกเป็น 3 ทีม 3 KPI แต่ในหัวลูกค้า เขาอาจรวมทั้งหมดเป็นแค่ “ใช้ง่ายหรือไม่ใช้ง่าย” เท่านั้นเองครับ
ดังนั้น EFA จึงไม่ได้เป็นแค่เทคนิคสถิติ แต่มันคือเครื่องมือที่ช่วยให้ธุรกิจเข้าใจ Mental Structure หรือโครงสร้างความคิดของลูกค้าจริง ๆ ว่าเขาจัดระเบียบประสบการณ์ต่าง ๆ ในหัวอย่างไรครับ
นั่นคือพลังของ EFA ครับ มันช่วยให้เราเห็นโลกอย่างที่ลูกค้ามองจริง ๆ ไม่ใช่อย่างที่นักการตลาดคิดเอาเอง โดยเฉพาะในบริบทใหม่ ตลาดใหม่ หรือกลุ่มเป้าหมายใหม่ ที่ทฤษฎีจากต่างประเทศอาจสะท้อนความจริงของตลาดไทยได้ไม่ครบ
KMO (Kaiser-Meyer-Olkin Measure of Sampling Adequacy) ก่อนทำ EFA ต้องดูก่อนครับว่าข้อมูลมีโครงสร้างร่วม พอที่จะค้นหา Factor ได้มั้ย ซึ่งเรามักจะดูจากค่า KMO โดย KMO มีหน้าที่วัดว่าข้อคำถามมีความสัมพันธ์กันในระดับที่เหมาะสมหรือเปล่า
ซึ่งเกณฑ์ที่ใช้โดยทั่วไปคือ KMO > .50 ถือว่าผ่านขั้นต่ำ, KMO > .70 ถือว่าดี และ KMO > .80 ถือว่าดีมาก ถ้าค่าต่ำกว่า .50 อาจหมายความว่าคำถามในแบบสอบถามกระจัดกระจายเกินไป หรือรวมเรื่องที่ไม่เกี่ยวข้องกันมากเกินไปจนหาโครงสร้างร่วมไม่ได้ครับ
Bartlett’s Test of Sphericity ค่านี้ทดสอบว่า Correlation ระหว่างข้อคำถามแตกต่างจากศูนย์อย่างมีนัยสำคัญหรือไม่ ถ้าข้อคำถามแทบไม่สัมพันธ์กันเลย ก็ไม่มีประโยชน์ที่จะทำ Factor Analysis ครับ เพราะไม่มี “แรงยึดเหนี่ยว” ระหว่างคำถาม เกณฑ์คือ Sig. < .05 ถ้าผ่าน แปลว่าข้อคำถามมีความสัมพันธ์กันเพียงพอที่จะนำไปวิเคราะห์ต่อได้
Factor Loading เมื่อเรารัน EFA เสร็จ หนึ่งในค่าสถิติสิ่งที่เราดูหลัก ๆ เลยคือ Factor Loading ซึ่งเป็นค่าความสัมพันธ์ระหว่างแต่ละข้อคำถามกับ Factor ครับ ยิ่ง Loading สูง ยิ่งหมายความว่าคำถามนั้นเป็นตัวแทนของ Factor ได้แข็งแรง
เกณฑ์ทั่วไปคือ Loading > .50 ถือว่าดี, > .70 ถือว่าแข็งแรงมาก ส่วนในงานวิจัยที่ต้องการความเข้มงวด เช่น วิทยานิพนธ์หรือบทความวารสาร ควรพยายามให้ทุก Item มี Loading อย่างน้อย .50 ขึ้นไป
แต่สิ่งที่ต้องระวังควบคู่กันคือ Cross Loading ซึ่งหมายถึงกรณีที่ Item หนึ่งข้อมี Loading สูงกับหลาย Factor พร้อมกัน ถ้าเกิดแบบนี้ แปลว่าคำถามข้อนั้นวัดได้คลุมเครือ และควรพิจารณาตัดออกหรือปรับภาษาใหม่ครับ
Cronbach’s Alpha Cronbach’s Alpha คือค่าสถิติที่ใช้ตรวจสอบว่าข้อคำถามในแต่ละกลุ่มมีความสอดคล้องกันภายในมากพอหรือเปล่า เกณฑ์ที่ยอมรับได้คือ Alpha > .70 ถือว่าพอใช้, > .80 ถือว่าดี แต่ต้องระวังว่าถ้า Alpha สูงเกินไป เช่น .95 ขึ้นไป อาจบ่งชี้ว่าคำถามซ้ำกันมากเกินไปจนไม่ได้เพิ่มข้อมูลใหม่ครับ
สิ่งสำคัญที่ต้องเข้าใจคือ Alpha บอกแค่ว่าข้อคำถามในชุดนั้น “สม่ำเสมอ” หรือเปล่า แต่ไม่ได้บอกว่าวัดสิ่งที่ถูกต้อง กล่าวคือ Reliability ไม่ใช่ Validity เครื่องมือที่ reliable อาจยังไม่ valid ก็ได้ หากข้อคำถามสม่ำเสมอในการวัดสิ่งผิด จึงต้องใช้ร่วมกับค่าสถิติอื่นเสมอ
Composite Reliability (CR) และ Rho_A เมื่อเข้าสู่บริบทของ CFA นักวิจัยมักหันมาใช้ Composite Reliability (CR) ร่วมกับ Alpha เหตุผลคือ Alpha สมมติว่าทุก Item มีน้ำหนักเท่ากัน แต่ในโมเดลจริงแต่ละข้อมี Loading ไม่เท่ากัน CR จึงถ่วงน้ำหนักตามค่า Loading จริงของแต่ละ Item ทำให้แม่นยำกว่าในบริบทนั้น
เกณฑ์ของ CR คือ > .70 ถือว่ายอมรับได้ > .80 ถือว่าดี ส่วนในงานวิจัยประเภท PLS-SEM มักพบค่า rho_A (Dijkstra-Henseler’s rho) ซึ่งมีค่าอยู่ระหว่าง Alpha และ CR และถือว่าเป็นตัวชี้วัด Reliability ที่เชื่อถือได้ในบริบทนั้น เกณฑ์คือ rho_A > .70 เช่นกัน
CFA ต่างจาก EFA อย่างไร ถ้า EFA คือการ “ปล่อยให้ข้อมูลพูด” CFA ก็คือการ “ถามข้อมูลว่าเห็นด้วยกับสิ่งที่เราคิดไว้ไหม” กล่าวคือ CFA เริ่มจากโมเดลที่นักวิจัยกำหนดไว้ตามทฤษฎีก่อน จากนั้นจึงทดสอบว่าโครงสร้างนั้นสอดคล้องกับข้อมูลจริงหรือไม่
ตัวอย่างเช่น ถ้าทฤษฎีบอกว่า Brand Experience ประกอบด้วย 4 มิติ ได้แก่ Sensory, Affective, Intellectual และ Behavioral CFA จะทดสอบว่าข้อมูลที่เก็บมาจากลูกค้าจริง ๆ รองรับโครงสร้าง 4 มิตินี้ไหม หรือบางมิติซ้ำซ้อนกันจนควรรวมเป็นหนึ่ง
CFA จึงเป็นด่านสำคัญก่อนที่จะเข้าไปสร้างโมเดลในขั้นต่อไป เพราะถ้าโมเดลการวัดยังไม่แข็งแรง ผลการทดสอบสมมติฐานเชิงสาเหตุก็จะไม่น่าเชื่อถือตามไปด้วย
Standardized Loading ใน CFA เช่นเดียวกับ EFA ใน CFA เราดู Standardized Factor Loading ของแต่ละ Item เพื่อตรวจว่า Item นั้นสะท้อน Construct ได้ดีแค่ไหน แต่ใน CFA จะเข้มงวดกว่า เพราะเรากำลังยืนยันโมเดลตามทฤษฎีที่ตั้งไว้เกณฑ์คือ Loading > .50 เป็นอย่างน้อย และ > .70 ถือว่าแข็งแรง ถ้า Item ใดมี Loading ต่ำมาก ควรพิจารณาตัดออก แต่การตัดต้องมีเหตุผลทางทฤษฎีรองรับเสมอ ไม่ใช่ตัดเพื่อให้ตัวเลขดูดีเท่านั้น
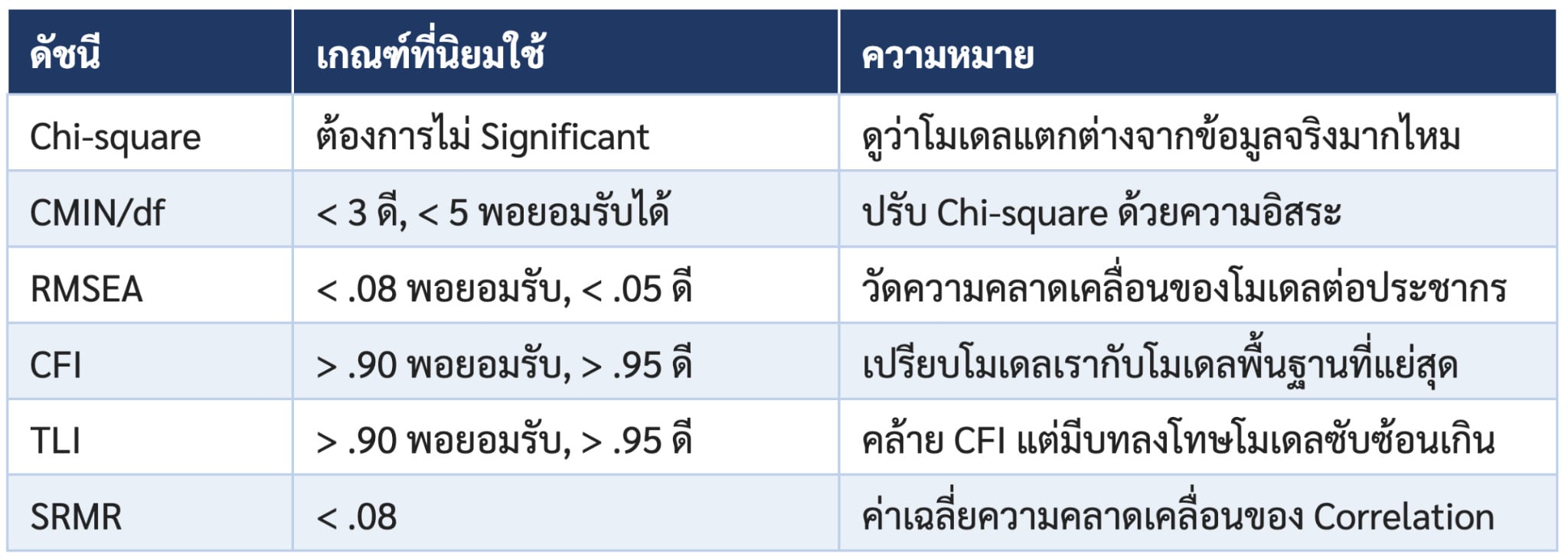
Model Fit โมเดลของเราตรงกับข้อมูลจริงแค่ไหน Model Fit คือหัวใจของ CFA เลยครับ เพราะเราต้องการรู้ว่าโครงสร้างทั้งหมดที่เราสร้างขึ้นนั้นสอดคล้องกับข้อมูลจริงระดับไหน ค่าที่ใช้มีหลายตัว เพราะไม่มีค่าใดตัวเดียวที่ตอบได้ทุกมิติ สามารถดูในตารางได้เลยครับ
สิ่งที่ต้องย้ำคือ อย่าปรับโมเดลเพื่อให้ค่า Fit สวยโดยไม่มีเหตุผล การเพิ่มความสัมพันธ์ระหว่าง Error Term หรือตัด Item ควรมีพื้นฐานทางทฤษฎีและบริบทเนื้อหารองรับ มิฉะนั้นก็เป็นแค่การไล่ตัวเลขเท่านั้น
Validity เครื่องมือวัดสิ่งที่ใช่จริงหรือเปล่า AVE และ Convergent Validity แม้จะผ่านทั้ง Reliability และ Model Fit แล้ว ยังต้องตรวจอีกขั้นว่า ตัวแปรแฝงแต่ละตัว “วัดสิ่งเดียวกัน” ได้จริงหรือเปล่า นั่นคือ Convergent Validity ค่าที่ใช้ตรวจหลักคือ AVE (Average Variance Extracted) ซึ่งวัดว่า Construct อธิบายความแปรปรวนของ Item ที่ใช้วัดมันได้มากแค่ไหน เกณฑ์คือ AVE > .50 หมายความว่า Construct อธิบายได้มากกว่าครึ่ง ส่วนที่เหลือเป็น Error ถ้า AVE ต่ำกว่านี้ แปลว่า Item ยังไม่ convergent กันดีพอ
โดยทั่วไปจะดู 3 อย่างร่วมกัน ได้แก่ Factor Loading ที่สูง, CR > .70 และ AVE > .50 ถ้าทั้งสามผ่าน ถือว่า Construct มี Convergent Validity ที่ดี
Discriminant Validity ตัวแปรต้องแตกต่างกันจริง ขั้นสุดท้ายของการตรวจ Validity คือการยืนยันว่า Construct แต่ละตัวในโมเดลนั้น “แตกต่างกันจริง” ไม่ใช่แค่ชื่อต่างกัน เช่น Brand Trust ต้องไม่เหมือนกับ Brand Satisfaction จนแยกกันแทบไม่ออก
วิธีที่ใช้กันมีสองแบบหลัก แบบแรกคือ Fornell-Larcker Criterion โดยตรวจว่า Square Root ของ AVE ของแต่ละ Construct ต้องมากกว่าค่า Correlation ระหว่าง Construct นั้นกับตัวอื่น แบบที่สองคือ HTMT (Heterotrait-Monotrait Ratio) ซึ่งปัจจุบันได้รับความนิยมมากขึ้น เกณฑ์คือ HTMT < .85 หรือ .90 แล้วแต่ความเข้มงวดของงาน
ถ้า Discriminant Validity ไม่ผ่าน ก็ต้องกลับไปตรวจสอบว่า Construct ทั้งสองนั้นควรจะแยกกันจริงหรือเปล่า หรือควรรวมเป็นตัวแปรเดียวกันในโมเดล
ข้อผิดพลาดที่พบบ่อยและวิธีหลีกเลี่ยง ข้อผิดพลาดที่ 1 ใช้ข้อมูลชุดเดียวทำทั้ง EFA และ CFA ในอุดมคติ ควรแยกชุดข้อมูลสำหรับ EFA และ CFA เพราะถ้าใช้ชุดเดียวกันอาจเกิด Overfitting คือโมเดลเข้ากับข้อมูลชุดนั้นดีมาก แต่ใช้กับกลุ่มอื่นได้ไม่ดีครับ
ข้อผิดพลาดที่ 2 ตัด Item เพียงเพื่อให้ Fit ดีขึ้น การตัด Item ควรพิจารณาทั้งค่าสถิติและทฤษฎีประกอบกัน ถ้าลบจนความหมายของ Construct หายไป งานวิจัยทั้งหมดจะสูญเสียความน่าเชื่อถือ
ข้อผิดพลาดที่ 3 ดู Cronbach’s Alpha อย่างเดียวแล้วสรุปว่าเครื่องมือดี Alpha วัดเพียง Reliability ไม่ใช่ Validity เครื่องมือที่ reliable อาจสม่ำเสมอในการวัดสิ่งที่ผิดได้ ต้องใช้ร่วมกับ EFA, CFA, AVE และ Discriminant Validity เสมอ
ข้อผิดพลาดที่ 4 แปลผลแบบไม่มีบริบทธุรกิจ งานสถิติที่ดีไม่ควรจบแค่ “ค่า Loading ผ่าน” แต่ต้องตอบต่อให้ได้ว่า ผลลัพธ์นี้บอกอะไรกับธุรกิจ และควรนำไปตัดสินใจอะไรต่อ
สรุป EFA และ CFA ในการ วิจัยการตลาด ถ้าจะสรุป EFA และ CFA ในการ วิจัยการตลาด ให้เห็นภาพในหนึ่งประโยค EFA ช่วยค้นพบว่าข้อคำถามจำนวนมากซ่อนมิติอะไรไว้ ส่วน CFA ช่วยยืนยันว่าโครงสร้างมิตินั้นแข็งแรงและเชื่อถือได้จริง
ระหว่างทางเราต้องดูค่าสถิติหลายตัวตั้งแต่ต้นน้ำอย่าง KMO และ Bartlett’s Test ไปจนถึงกลางน้ำอย่าง Loading, Alpha, CR และ AVE และปลายน้ำอย่าง Model Fit กับ Discriminant Validity แต่ตัวเลขเหล่านี้เป็นเพียงหลักฐาน หน้าที่ของนักวิจัยและนักการตลาดคือการแปลหลักฐานนั้นให้กลายเป็นความเข้าใจลูกค้าที่ลึกพอจะนำไปตัดสินใจได้จริง
EFA และ CFA จึงไม่ใช่แค่เครื่องมือสำหรับทำวิทยานิพนธ์ให้ผ่าน แต่เป็นกระบวนการสร้าง Measurement ที่แข็งแรง เพื่อให้ธุรกิจมีข้อมูลที่แม่นขึ้น เข้าใจลูกค้าลึกขึ้น และตัดสินใจเชิงกลยุทธ์ได้มั่นใจมากขึ้นในทุกสถานการณ์ครับ
บทความที่แนะนำให้อ่านต่อ